
In 10 minuten leg ik de begrippen data-ondersteund onderwijs, learning analytics en AI uit.
Learning Analytics
14 posts
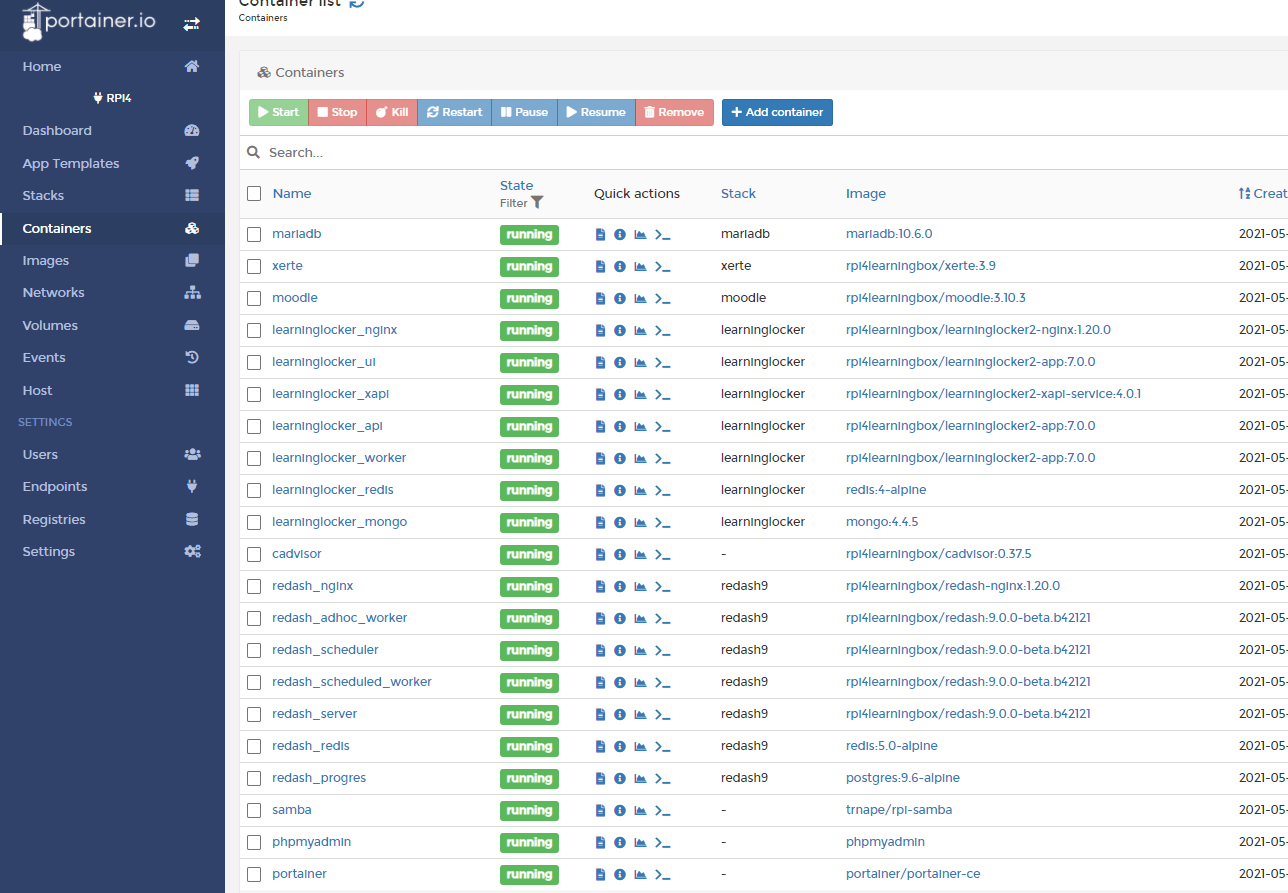
Het begon als een eenvoudige vraag: “kun je uitleggen hoe je Xerte binnen Docker kunt draaien?” en het eindigde (nou ja, gaat eindigen) in een toolset die bestaat uit Xerte (uiteraard), MariaDB (als database voor Xerte en Moodle), Tsugi (zodat Xerte ook LTI aankan), Moodle (als leeromgeving om de Xerte leerobjecten in te hangen), Learning Locker (LRS om de xAPI data […]

Ik zal maar meteen met de deur in huis vallen: ik was enigszins teleurgesteld gisteren na het webinar van SURF over de uitgevoerde markt- en technologieverkenning op het gebied van learning analytics. De beloofde resultaten waren: [na afloop van het webinar…] Heb je een beter beeld van de ontwikkelingen rond LA, privacy en AVG en de rol van SURF. Begrijp je […]
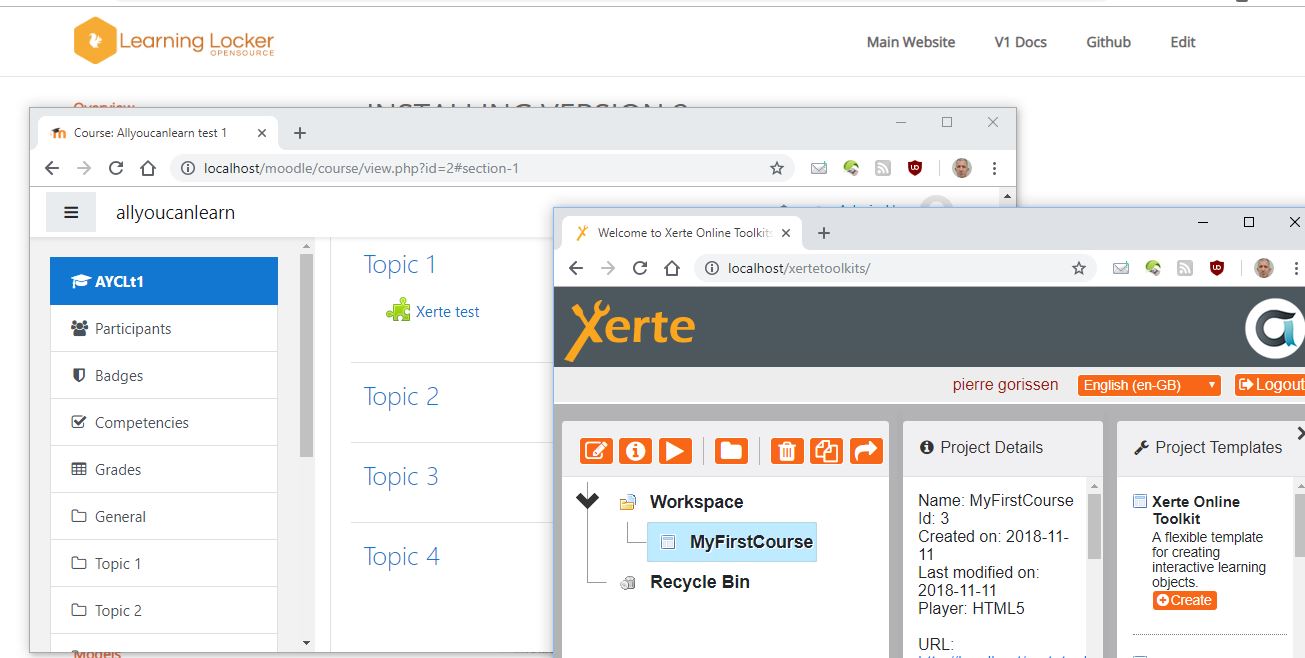
Net als Wilfred Rubens was ik bij de sessie van Deltion College en het Erasmus MC vorige week woensdag bij de SURF Onderwijsdagen 2018. Je kunt zijn verslag hier lezen. Zoals ik al zei, ik kon me wel vinden in het label “pionier” vanwege de bijbehorende omschrijving. Ik wordt graag praktisch en leer deels door dingen gewoon uit te proberen. Dus toen […]
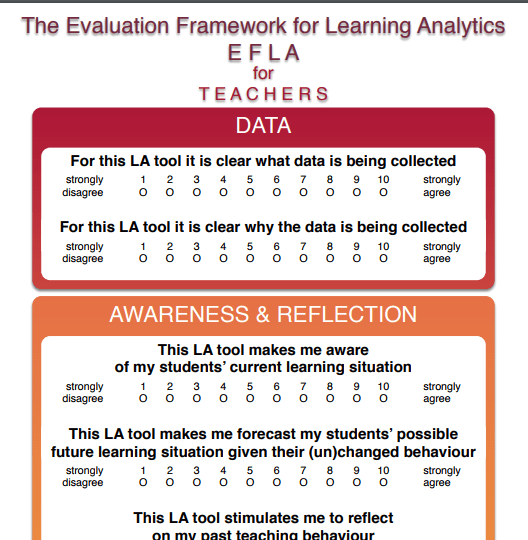
Bij learning analytics gaat het om het meten, verzamelen, analyseren en rapporteren van en over data van leerlingen en hun context, met als doel het begrijpen en optimaliseren van het leren en de omgeving waarin dit plaatsvindt. De terugkoppeling van deze analyses kan leiden tot effectiever handelen door de leraar, leerling of bijvoorbeeld de ontwikkelaar van lesmateriaal (Woning, 2012). Het is […]

OK, ik zal het meteen toegeven. Als je een spreker op het programma hebt staan met als omschrijving “Quantified Self goeroe van Nederland en daarbuiten” dan scoor je bij mij geen pluspunten. Maar dat is niet de reden dat ik op 8 december a.s. niet aanwezig ben in Deventer bij de Quantified Student 2016 conferentie. Het past simpelweg niet in mijn […]
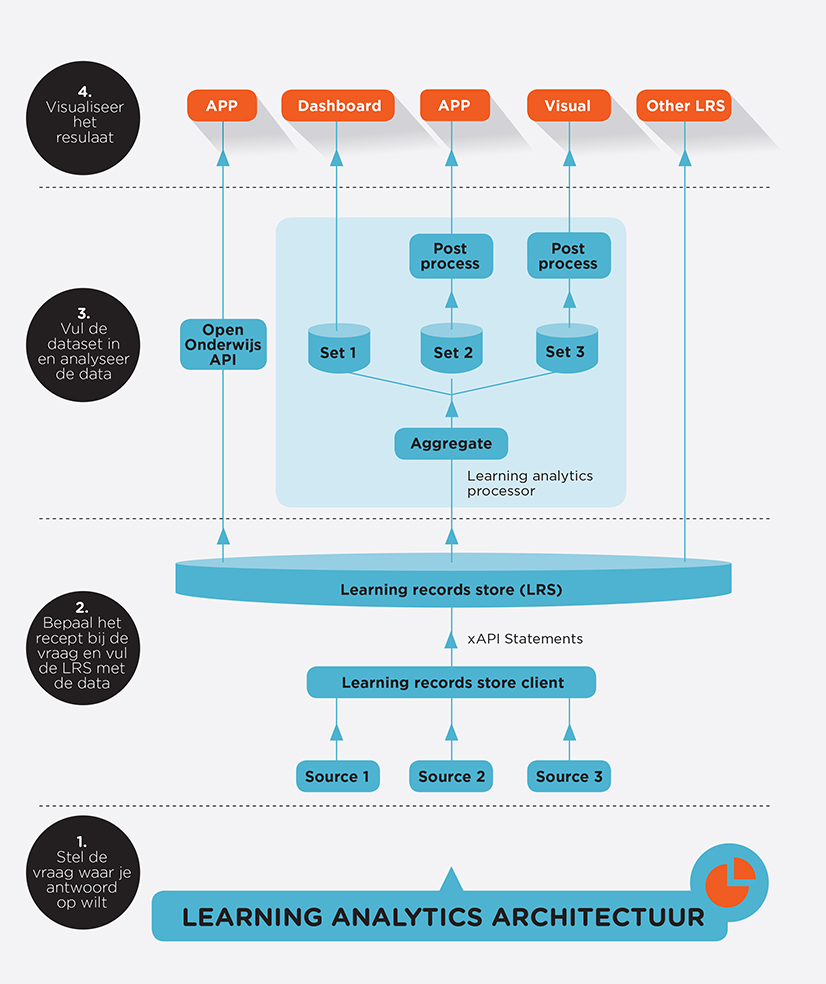
Ik weet niet exact waar Learning Analytics zich inmiddels bevind op de meest recente hype cycle grafieken van Gartner (en ik heb het voor deze blogpost niet nagezocht omdat het me niet écht uitmaakte), maar afgaande op wat ik zo om me heen hoor is de eerste “hype” er wel een beetje vanaf. Geluiden als “we moeten studenten niet tot getallen […]

Het is inmiddels 23:00 uur geweest, dus dit verslag van de preconference over Learning Analytics tijdens Dé Onderwijsdagen 2015 is wat compacter. Hele korte conclusie ook op basis van de gesprekken tijdens het diner: nuttige samenvatting en overzicht van stand van zaken, eigenlijk teleurstellend dat we nog maar zó weinig bereikt hebben. OK, dat tweede deel klinkt wellicht erg negatief, daarom […]

{kind=link}
Als ik kan kiezen tussen het lezen van een boek of het bekijken van de film naar aanleiding ervan, dan kies ik altijd voor de film. Vandaag was het potentieel nog erger: ik had het rapport over Learning Analytics en de Wet Bescherming Persoonsgegevens al gelezen in de trein op weg naar de preconference van Dé Onderwijsdagen 2015 in Rotterdam. Maar gelukkig […]
Geen tijd voor een uitgebreide blogpost, wel een paar interessante links vandaag: Twee e-learning opleidingen die (weer) in september 2014 starten De livestream van de 2e Learning Analytics Summer Institutes (LASI 2014) Kaart met Open Streetmap dekking wereldwijd Open Education Handbook