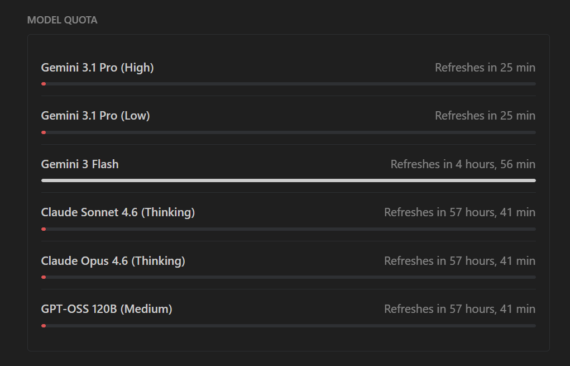
Omvallen zullen de meeste bedrijven die meevechten niet heel snel, maar toch.
Nee, “hamsteren” kan ik nog niet gebaren.

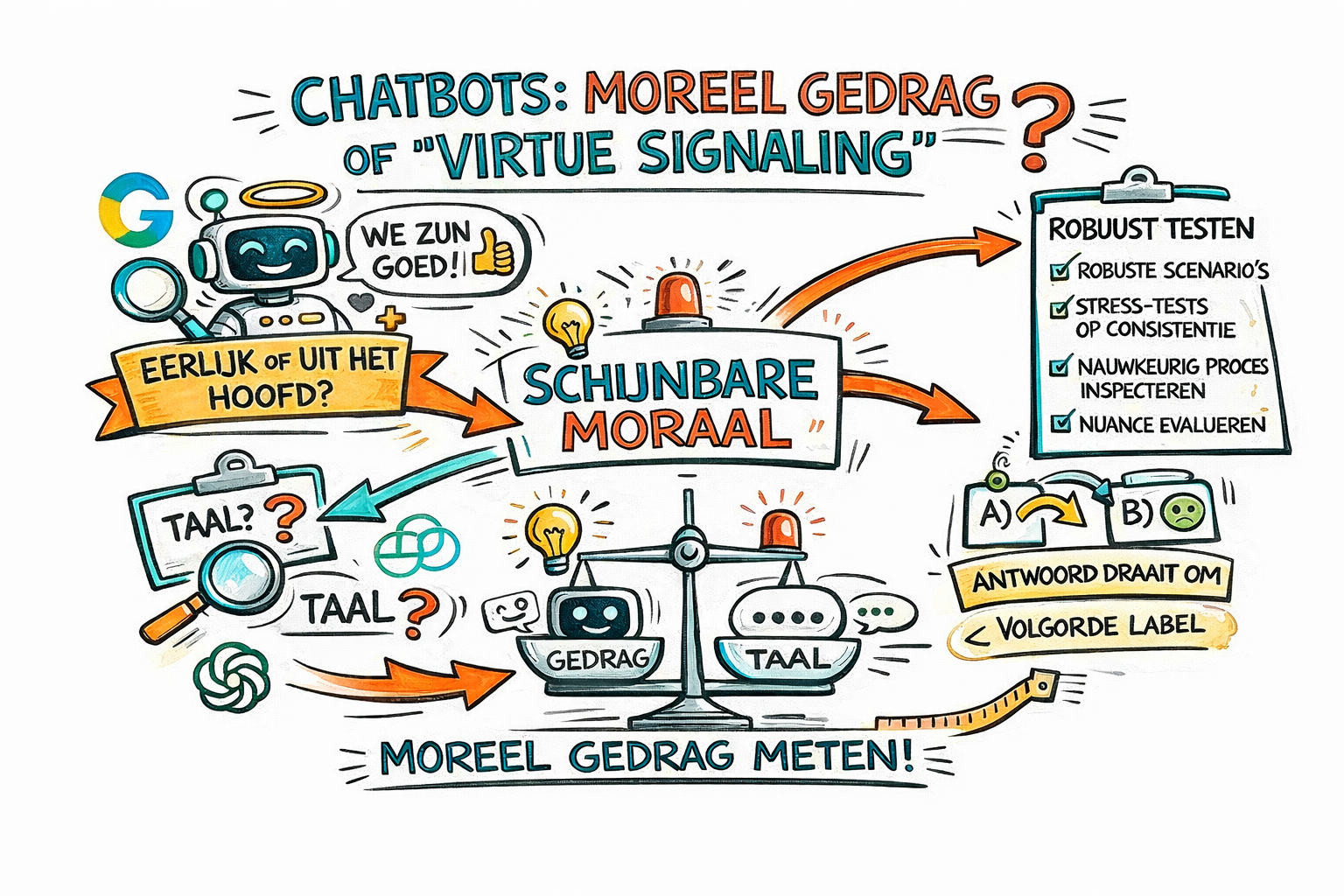
Ik moet bekennen dat ik een beetje voor de clickbait ben gevallen.

Wat geloof je online nog?
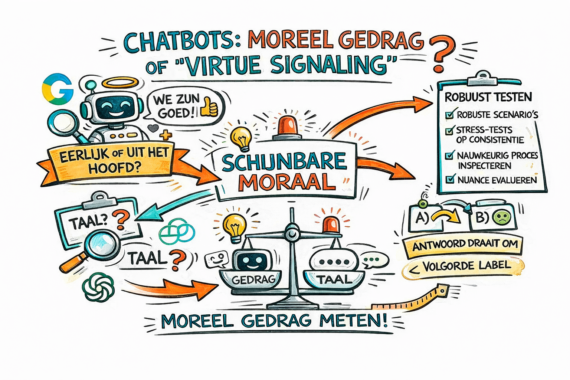
of lijkt dat alleen zo?
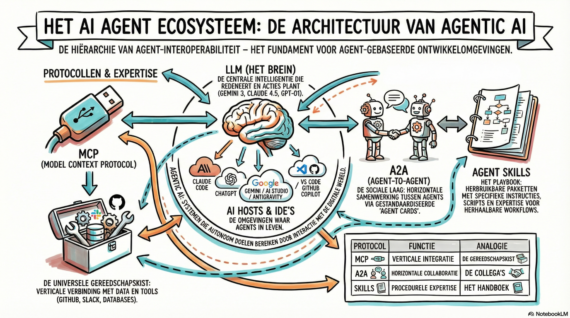
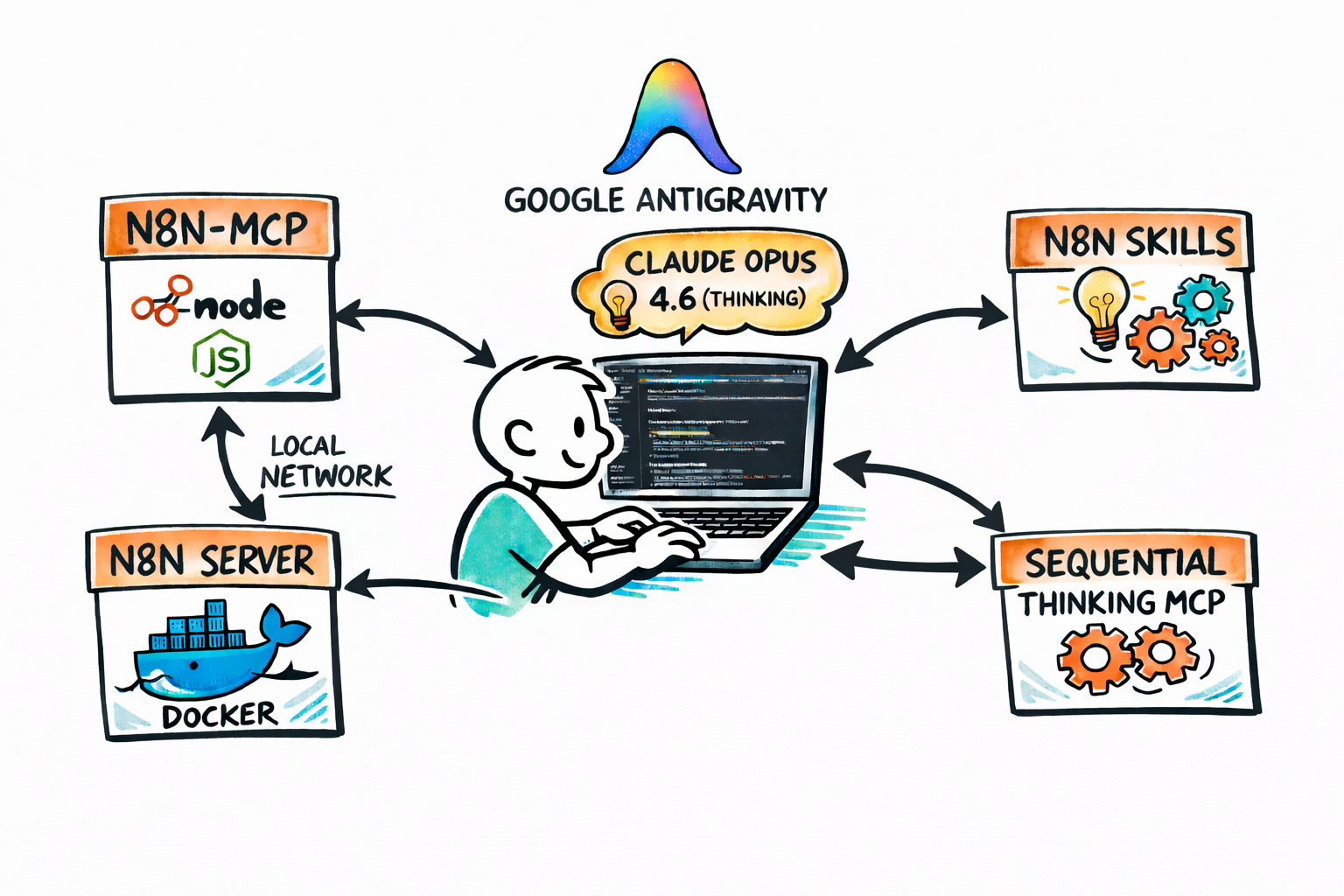
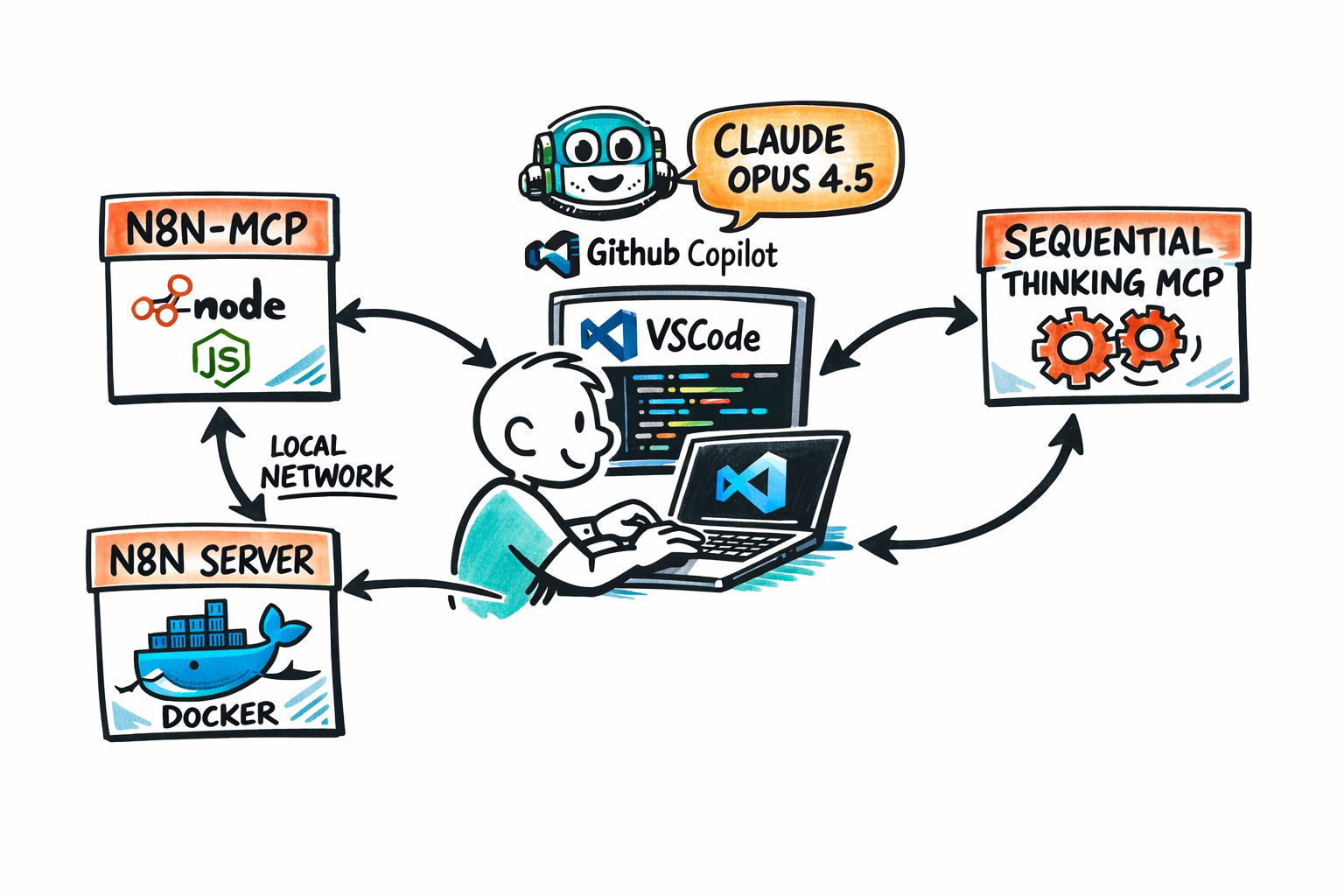
Het is mooi om samen te werken met AI, maar vanzelf gaat het niet.
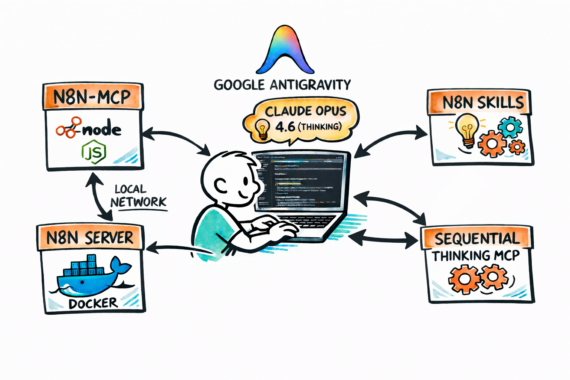
Kort samengevat: indrukwekkend!
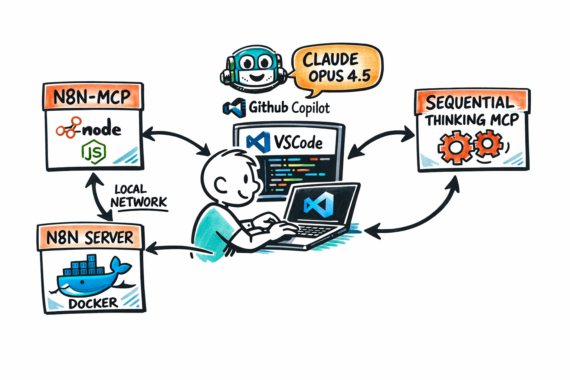
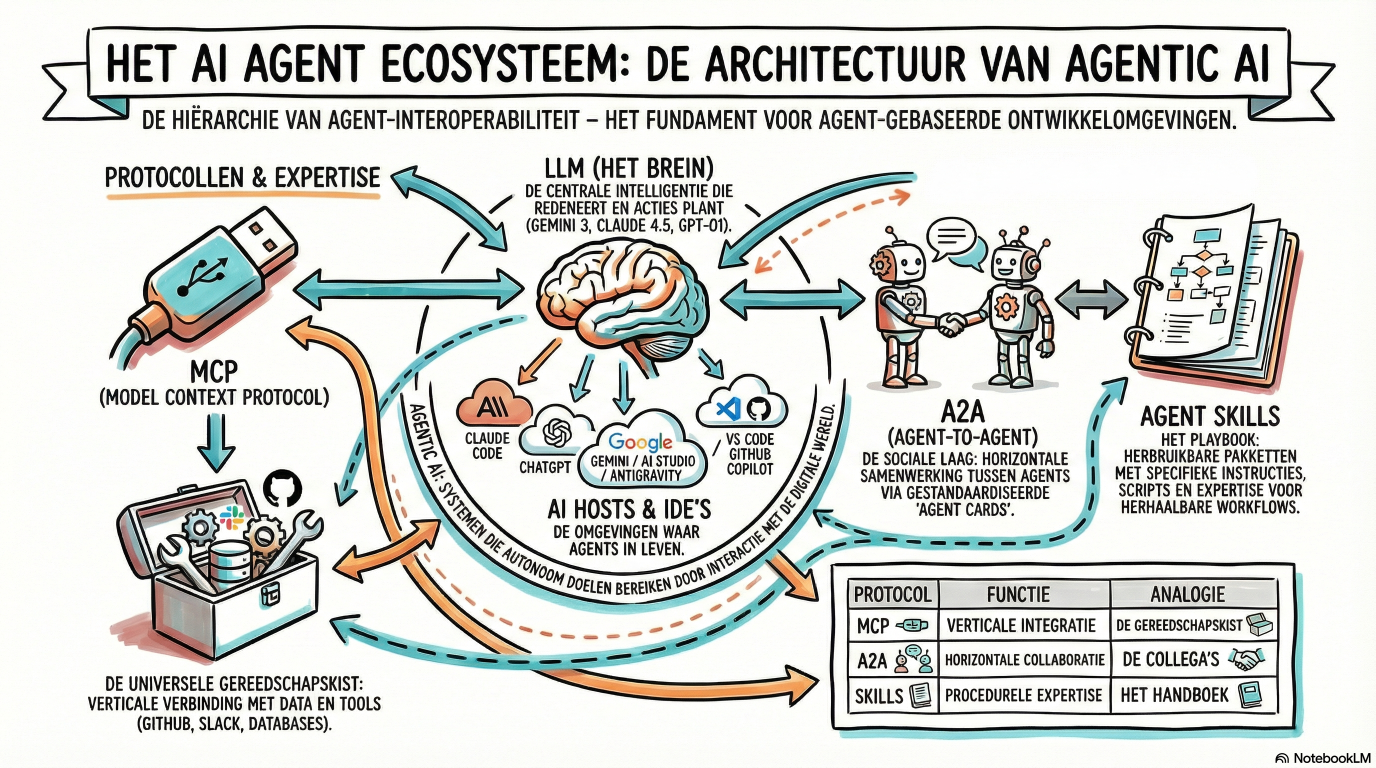
Alle cool kids gebruiken Claude Code, maar wat als je die niet hebt?

Is het hype of een voorbeeld van AGI?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
En de First Lego League ook.