
Ontdek wat onderzoek en praktijk van elkaar kunnen leren tijdens *Kom over de brug* voorafgaand aan de @ORD_2018 Het @iXperium Centre of Expertise Leren met ict verzorgt de track "De digitale samenleving: een leven lang leren en lesgeven met ict" https://t.co/PzVdLbcmZY @HANnl pic.twitter.com/276UF0TfdT — Pierre Gorissen (@PeterMcAllister) April 4, 2018
Onderzoek
73 posts
Tijdens mijn promotieonderzoek heb ik veel gebruik gemaakt van SQL-server (daar zat de logdata van de opnames van de colleges waar ik onderzoek naar deed in) en SPSS (als toen meest voor de hand liggend statistiekpakket). Ik heb sindsdien al vaker geconstateerd dat als ik nú nogmaals dat onderzoek zou doen ik waarschijnlijk in ieder geval SPSS zou hebben vervangen door […]

Vanochtend is Stephen Hawking overleden. Hij heeft gelukkig veel langer mogen leven dan de 2 jaar die artsen hem gaven toen hij op 21-jarige leeftijd de diagnose ALS kreeg. Ik blijf het ook diep indrukwekkend vinden hoe hij, ondanks zijn lichamelijke beperkingen, tóch zo veel heeft kunnen bereiken. Rust zacht.
In de categorie “Wauw” valt dit artikel (pdf) van onderzoekers bij Carnegie Mellon University. Zij hebben een manier bedacht om 3D-modellen die je normaal gesproken naar een 3D-printer zou sturen om te zetten naar instructies voor een machinale breimachine. In plaats van een hard konijn uit PLA of ABS krijg je dan een zacht, knuffelbaar konijn. Op de projectsite staan een filmpje met […]
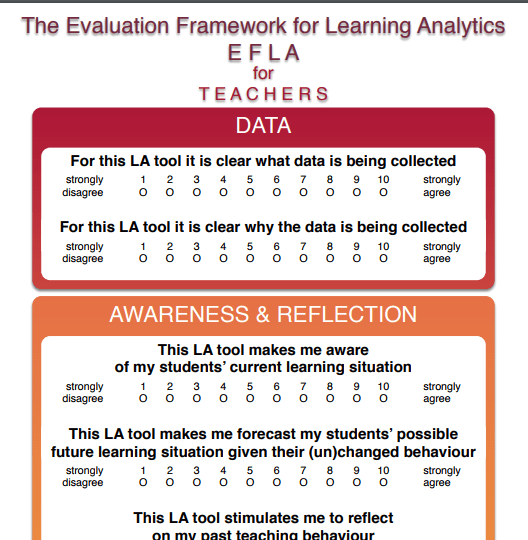
Bij learning analytics gaat het om het meten, verzamelen, analyseren en rapporteren van en over data van leerlingen en hun context, met als doel het begrijpen en optimaliseren van het leren en de omgeving waarin dit plaatsvindt. De terugkoppeling van deze analyses kan leiden tot effectiever handelen door de leraar, leerling of bijvoorbeeld de ontwikkelaar van lesmateriaal (Woning, 2012). Het is […]

Als ik op Google zoek op “van gelijk hebben naar gelijk krijgen” kom ik ook berichten tegen met titels als “Wil je gelukkig zijn of gelijk krijgen?” die niet helemaal hetzelfde bedoelen als wat ik wilde zeggen. De aanleiding is dit bericht getiteld “Why mythbusting fails: A guide to influencing education with science“. Het bericht trekt een analogie tussen de discussie […]

We hebben het druk! En daarom zijn we voor het iXperium/Centre of Expertise Leren met ict per direct op zoek naar een praktijkgerichte (senior) onderzoeker en een praktijkgerichte junior onderzoeker. Beide 0,8-1,0 fte

Via de site van het NRO kwam ik bij het peilingsonderzoek Natuur en Techniek. Ik citeer even wat het NRO er zelf over schrijft: De Inspectie van het Onderwijs publiceerde op 31 mei 2017 als onderdeel van Peil.Onderwijs het peilingsonderzoek Natuur en Techniek. Peil.Natuur en Techniek geeft inzicht in het aanbod van basisscholen, de prestaties van leerlingen in groep 8 en de […]
Op woensdag 10 mei 2017 organiseert de VOR divisie ICT een bijeenkomst in Eindhoven. Tijdens deze bijeenkomst komen promovendi aan het woord bij wie ICT een rol speelt in hun onderzoek. De onderwerpen zullen heel divers zijn, soms wat meer technisch, in andere gevallen meer op onderwijs gericht. Het zal ook altijd nog “onderzoek in uitvoering” zijn. Daarom zijn de presentaties […]

{kind=link}
{kind=link}
Welke rechten heeft een slimme robot? Is het/hij/zij een persoon of een ding? Welke plichten hebben robots? En hun ontwerpers? Het is tijd voor de EU om daar iets van te vinden.