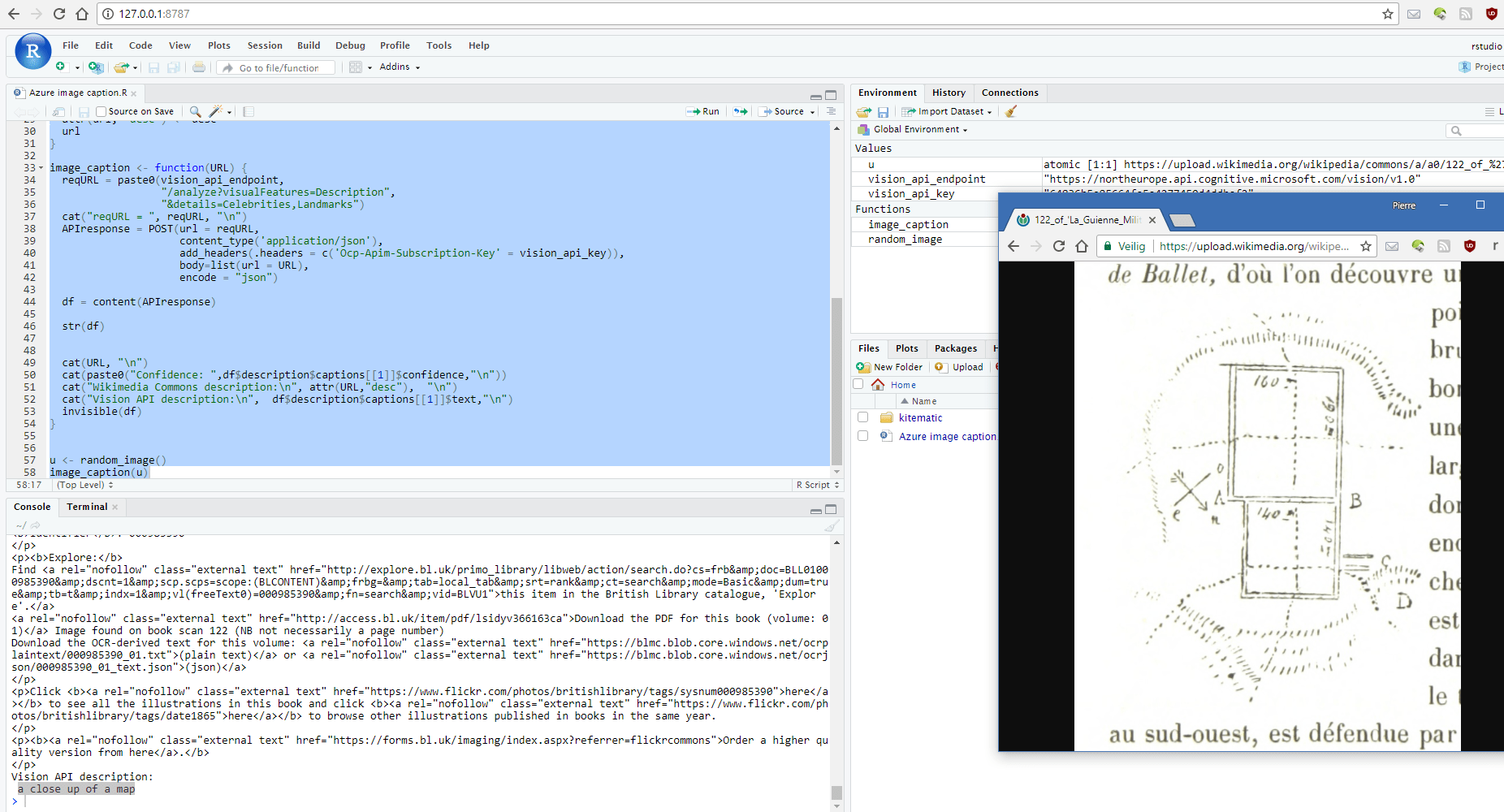
Vond ik afgelopen weekend nog dat Docker toch best wel een leercurve had, vandaag kwam ik er gelukkig al achter dat die geïnvesteerde tijd toch niet voor niets was geweest. Want op het Revolutions weblog stond een interessant bericht. Daarbij werd gebruik gemaakt van de Microsoft Azure Computer Vision API om automatisch een bijschrijft te laten genereren van willekeurige afbeeldingen die opgehaald werden […]
R
6 posts

Shiny is een framework voor R waarmee je (semi-) eenvoudig webapplicaties kunt maken. Een voorbeeld van zo’n applicatie kun je hier vinden, met daarbij de opmerking dat die draait op de alfa-service van shinyapps.io en af en toe een foutmelding kan geven (bijvoorbeeld dat hij qplot niet kan vinden). Dan moet je de pagina even verversen. De code voor die applicatie […]
Het is, zo te lezen, nog een werk in uitvoering, maar Lively R, een uitbreiding op R die op haar beurt weer gebruik maakt van een aantal andere uitbreidingen, ziet er nu al heel interessant uit. Zoals je in het filmpje hierboven kunt zien, kun je interactief met de data aan de slag. Vooral handig in het eerste analyserende deel van […]
Het is even wat druk hier. Komend weekend is de deadline voor de projectopdrachten van twee MOOCs waar ik aan deelneem (Practical Machine Learning en Developing Data Products, beiden onderdeel van de Data Science specialisation) en die vergen even wat werk. Deze post is vooral ook voor mezelf even een link naar de instructies hoe ik een Slidfy presentatie op GitHub […]
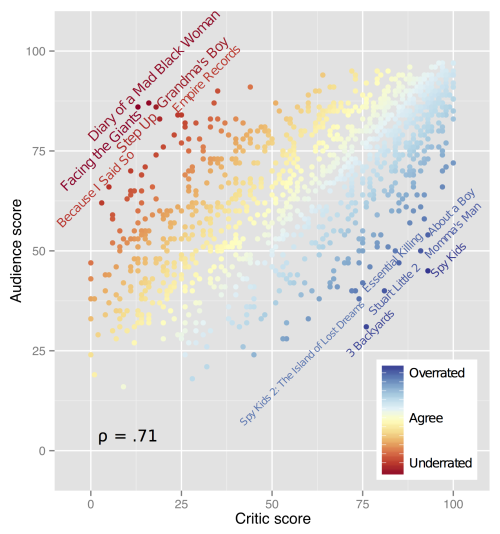
Terwijl ik nog even aan het wachten ben op de definitieve beoordeling van twee MOOCs die onderdeel uitmaken van de Data Science specialisatie op Coursera en aan het inschatten ben hoeveel ik er nu tegelijkertijd er bij wil/kan doen, kom ik zo nu en dan van die mooie ‘onderzoekjes’ tegen die laten zien hoe je tamelijk subjectieve inschattingen (is een film […]
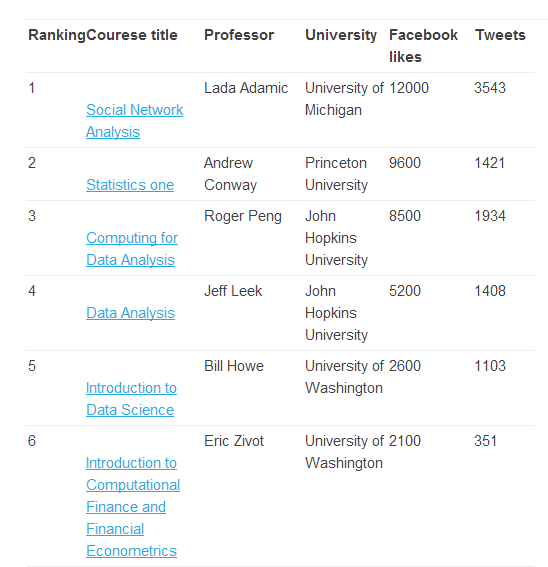
Toen ik op 22 september jl. begon aan de MOOC Statistics One, verzorgd door Andrew Conway van de Princeton Universiteit, was R als programma voor mij nog een volledig onbekend iets. D.w.z. ik had er wél van gehoord, ik wist dat er mensen waren die er heel interessante dingen mee voor elkaar kregen, maar voor mij was de omgeving nog een […]