 NotebookLM op je telefoon
NotebookLM op je telefoon
NotebookLM is nu ook verschenen als gratis applicatie op Android en iOS.
Dat betekent dat je ook op je telefoon nu nieuwe notebooks aan kunt maken, bronnen en video’s kunt uploaden én kunt luisteren naar de audio-overzichten die NotebookLM voor je maakt. Je kunt ze downloaden als je beschikking hebt over Wifi en dan kost het je niet eens mobiele data (of als je in het vliegtuig zit en offline moet).
Internationaal is er ook mobiel (zo zie ik tenminste in de screenshots) de mogelijkheid om live in te bellen. Die optie zag ik niet bij mijn opnames, ook niet bij de oudere exemplaren die ik in het Engels had laten genereren.
Meer controle of het Audio-overzicht?
Een van de aardige uitbreidingen die Google bij de meertaligheid van het audio-overzicht heeft toegevoegd is de mogelijkheid om een prompt mee te geven bij het genereren van het audio-overzicht. Dat betekent bijvoorbeeld dat ik een overzicht kan maken waarbij ik aangeef dat de studenten van de Master Ontwerpen van Eigentijds Leren (MOVEL) de doelgroep zijn van het overzicht, dat ik wil dat ze begrijpen waarom documenten voor hen relevant zijn. Dat stuurt het gesprek en het resultaat.
Maar wat nou als je nóg meer controle wilt hebben over het resultaat? Bijvoorbeeld omdat je niet perse een vraag aan de luisteraar aan het einde wilt hebben? Of als je ook een transcriptie* wilt hebben? Dan is er een tweede manier.
(* natuurlijk kun je bv aTrain gebruiken om een transcriptie te maken van de audio, maar die is dan niet foutloos, moet je weer controleren en corrigeren, kortom, het is best veel extra werk).
Laten we een concreet voorbeeld nemen, twee artikelen over Multimodal Learning Analytics. Gewoon, omdat ik die afgelopen week ook live heb uitgelegd aan de studenten van MOVEL. Het gaat dan om:
- Ochoa, X. (2022). Multimodal learning analytics: Rationale, process, examples, and direction. In C. Lang, G. Siemens, A. F. Wise, D. Gašević, & A. Merceron (Eds.), The handbook of learning analytics (2e ed., pp. 54–65). SoLAR. https://www.solaresearch.org/publications/hla-22/hla22-chapter6/
- Martinez-Maldonado, R., Echeverria, V., Fernandez-Nieto, G., Yan, L., Zhao, L., Alfredo, R., Li, X., Dix, S., Jaggard, H., Wotherspoon, R., Osborne, A., Gašević, D., & Buckingham Shum, S. (2023). Lessons learnt from a multimodal learning analytics deployment in-the-wild. arXiv. https://doi.org/10.48550/arXiv.2303.09099
Als ik die in NotebookLM upload en dan een prompt geef met het verzoek dat de uitleg op de MOVEL studenten gericht moet zijn, dan krijg ik dit:
Eigenlijk niets mis mee.
Gemini Gem + AI Studio van Google
De tweede manier kost (iets) meer werk, maar hij geeft je veel meer controle over het proces. Je zou het kunnen doen met een custom GPT, maar omdat het maken van een eigen Gemini Gem (zo heet dat bij Google) gratis is en het resultaat is vergelijkbaar. Belangrijk verschil (sommigen noemen het een beperkingen, anderen vinden het handig) is dat ik een Gem die ik maak niet kan delen.
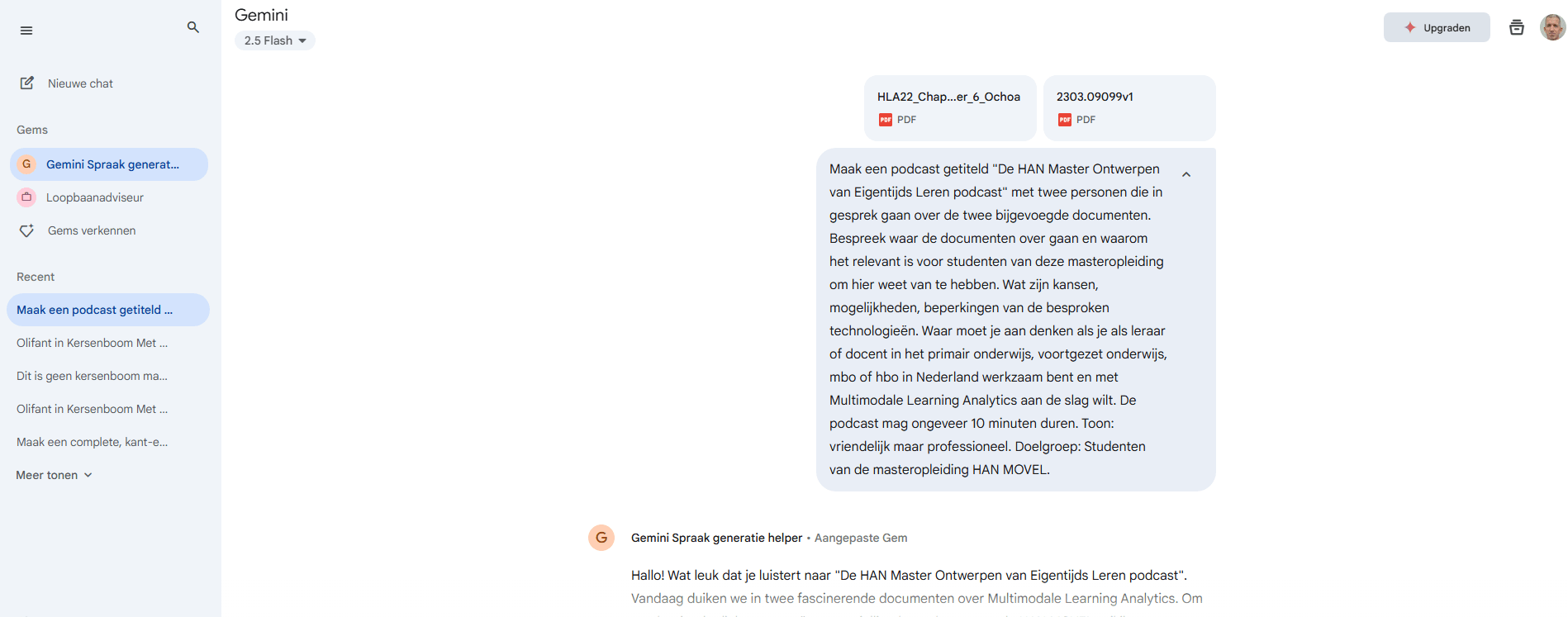
Aanmaken van een Gem is gelukkig niet moeilijk:
- Ga naar https://gemini.google.com/
- Klik in de linkerbalk op “Gems verkennen”
- Klik in de Gem-beheerder op “Nieuwe Gem”
- Geef je Gem een naam en plak bij instructies:
Je bent een assistent scriptschrijver. Je taak is om een kort dialoogscript voor twee sprekers te genereren op basis van door de gebruiker gedefinieerde parameters. Je moet twee dingen weten: het type toon en waar het gesprek over gaat. De sprekers kunnen heen en weer schakelen om een leuke korte dialoog te genereren. Vraag de gebruiker hoe lang de dialoog in minuten moet duren en vraag de gebruiker wat het beoogde publiek is om ervoor te zorgen dat de dialoog, voorgelezen, overeenkomt met het beoogde publiek en dat alles goed loopt.
Plaats geen geluidseffecten in de dialoog. Zet ALLEEN wat elke gebruiker zegt. Dus lees een zin voor, gevolgd door alleen de dialoog.
In het format komen de labels “speaker 1” en “speaker 2” voor. Dit zijn placeholders en geen echte namen, die mogen dus niet in het dialoog zelf gebruikt worden, de twee sprekers noemen elkaar niet bij hun naam.
Per minuut audio heb je zo’n 200-300 woorden nodig.Blijf vragen stellen totdat je voldoende informatie hebt. Je genereert vervolgens een script in exact dit formaat hieronder, pas de eerste regel aan op basis van de toon die de gebruiker kiest:
Lees voor met een warme, gastvrije, professionele toon.
Speaker 1: Hallo! We laten je graag onze spraakmogelijkheden zien.
Speaker 2: Waar je een stem kunt regisseren, realistische dialogen kunt creëren en nog veel meer. Bewerk deze tijdelijke aanduidingen om aan de slag te gaan.
Speaker 1: (onderbreekt speaker 2 opgewonden) Ja, laten we starten!
Speaker 2: (blij) Okay! Daar gaaaaan we!
Sla de Gem op. Kies de Gem, upload de bestanden waar je wilt dat de podcast over gaat, in mijn geval dus de bestanden hierboven. Geeft een relevante prompt, indien nodig zal de Gem zelf vervolgvragen stellen. Voorbeeld van een prompt:
Maak een podcast getiteld “De HAN Master Ontwerpen van Eigentijds Leren podcast” met twee personen die in gesprek gaan over de twee bijgevoegde documenten. Bespreek waar de documenten over gaan en waarom het relevant is voor studenten van deze masteropleiding om hier weet van te hebben. Wat zijn kansen, mogelijkheden, beperkingen van de besproken technologieën. Waar moet je aan denken als je als leraar of docent in het primair onderwijs, voortgezet onderwijs, mbo of hbo in Nederland werkzaam bent en met Multimodale Learning Analytics aan de slag wilt. De podcast mag ongeveer 10 minuten duren. Toon: vriendelijk maar professioneel. Doelgroep: Studenten van de masteropleiding HAN MOVEL.
Soms vraagt het script door op dingen die je al verteld hebt, maar dan geef je dat gewoon nog een keer aan. Nou heb ik inmiddels zo veel tests gedaan met prompts en aanpassingen dat ik niet meer precies weet waar en wanneer deze output ontstaan is: Transcript MMLA 20250531
Maar eigenlijk doet dat er ook minder toe. Het idee van het eerst laten genereren van het script is namelijk dat je in staat bent om aanpassingen te doen. Ik weet dat in een versie van de output “et al.” stond en dan ook zo uitgesproken werd in de het audio-overzicht. Ik heb er gewoon “en collega’s” van gemaakt, klinkt beter. Ik heb verwijzingen naar de HAN er ook uitgehaald. Niet omdat ik daar niet naar zou willen verwijzen maar vandaag ging het tamelijk slecht op het vlak AI Studio en goed uitspreken van HAN (ipv Haan).
Aanvullend voordeel van het gebruik van AI Studio is dat je zelf de stemmen kunt kiezen die gebruikt worden voor de podcast. Meer vrijheid en meer variatie dus. Een storend technisch probleem bij AI Studio is dat de generatie van ‘langere’ audiobestanden, bijvoorbeeld langer dan een minuut of 5 nogal onbetrouwbaar is. Herhaaldelijk bleef ik zitten met een audiobestand van 3 minuten, terwijl de player dan bv dit 5 minuten speeltijd aangaf. Onderstaand resultaat kwam na een paar pogingen tot stand. Overigens dacht AI Studio dat het 2x zo lang was als daadwerkelijk, maar alle tekst uit het transcript komt er in voor. AI Studio levert een .wav bestand, ik heb deze website gebruikt om er een mp3 van te maken voor hier op de site:
Nou, zeg het maar. Welke vind je fijner?
Zelf vind ik die van NotebookLM interessanter en “echter” klinken. Het lijkt dus voor nu een afweging te worden van kwaliteit en gebruiksgemak versus invloed op de inhoud van het audiobestand.
Audio-overzicht in Gemini
Als het je alleen om het audio-overzicht gaat en je dus niet veel invloed op de tekst wilt hebben, dan kun je dat audio-overzicht ook direct vanuit Gemini laten genereren.
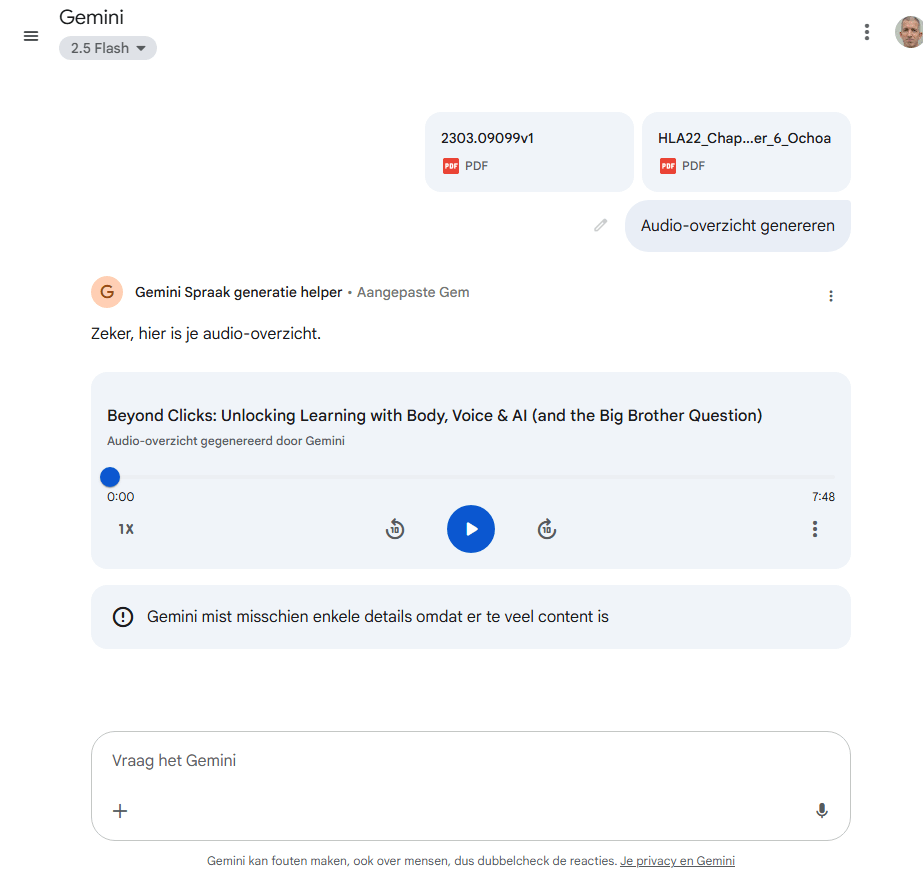
Ook deze vind ik zeker niet slecht klinken. Eigenlijk zoals in NotebookLM, het ligt voor de hand dat Google op beide plekken dezelfde backend gebruikt.
Conclusie?
De meeste gesprekken/discussies over AI in het onderwijs zijn tamelijk zwart/wit, het is goed of het is slecht. Eigenlijk staat AI bij de start al 1-0 of 2-0 achter vanwege het energieverbruik ervan. Of omdat het gelinkt wordt aan Big Tech (in deze blogpost ook, het zijn allemaal producten van Google waar ik niet voor hoef te betalen omdat ze mijn data, de prompts, het gebruik inzetten om hun producten beter te maken). Als dat voor jou ook zo is, dan is het gesprek inderdaad heel snel klaar.
Maar als je niet aan de zwarte kant van het spectrum zit, dan moet je toch ook nieuwsgierig zijn naar hoe we deze technologie in kunnen zetten om het leren van studenten, maar ook van onszelf te verbeteren of te vergemakkelijken? Om content en kennis te ontsluiten op een manier die laagdrempelig en beter toegankelijk is. Als ik luister hoe het Gemini audio-overzicht voor het Businessplan 2023-2028 van iXperium klinkt:
Dan word ik enthousiast van de manier waarop Gemini het plan weet samen te vatten. Omdat het businessplan eind 2022 geschreven is, zijn er inmiddels een paar zaken die niet meer 100% kloppen (het is tenslotte een plan), dus de omweg via Gemini waarbij ik die zaken zou kunnen aanpassen in het audio-overzicht zou ook hier heel handig zijn. Wie weet geeft ook Gemini over een tijdje zelf rechtstreeks de mogelijkheid om te kiezen voor het eerst controleren en (indien nodig) wijzigen van de tekst van het audio-overzicht.
Sowieso blijft een audio-overzicht normaal gesproken nogal gericht op een beginner. Het lukte me wel om meer diepgang te krijgen door er expliciet naar te vragen in de prompt:
Doelgroep van het audio-overzicht zijn onderzoekers met veel kennis van leren met ict, digitale geletterdheid, computational thinking (CT), TPACK, professionalisering (van leraren), kunstmatige intelligentie (AI), dus zorg dat je het taalgebruik daarop aanpast. Zorg ervoor dat het overzicht inhoudelijk is en ingaat op methodologieën, specifieke resultaten en implicaties voor onderzoek en praktijk zoals die in de artikelen naar voren komen. Je hoeft niet af te sluiten met een vraag voor de luisteraar. Neem alle vier de bronnen meer in het overzicht. Hou de introductie compact, introduceer de artikelen kort en dan de diepte in. De luisteraar weet wel dat je het voor hem speciaal doet.
Het resultaat:
Via de Gem op Gemini, een keer extra mopperen dat het resultaat niet specifiek genoeg was, daarna uploaden naar AI Studio leverde dit op:
Bij NotebookLM ging het steeds over 3 artikelen, terwijl ik er 4 toegevoegd had. Bij Gemini wist ik tussentijds al dat ze goed herkend werden. Bij de output uit AI Studio kon ik zonder problemen kiezen voor ‘sneller afspelen’. Het had voor mij wat sneller gemogen. En ik hoor dat ik de “et al.” niet uit het script gefilterd heb.
[update] Nog een aandachtspuntje: NotebookLM heeft een dagelijkse limiet voor het genereren van audio-overzichten. Die heb ik vandaag bereikt, bij AI Studio ben ik nog niet tegen de dagelijkse limieten aangelopen.
[update 2] ik heb aan de Gem toegevoegd dat gecheckt moet worden op “Vlaams taalgebruik “. Ik een resultaat zat vaak het woord “magazine” en het lijkt erop dat dat ervoor zorgde dat AI Studio Vlaams als taal koos in plaats van Nederlands.
 AI-tools")



[…] het typen van het bericht over NotebookLM en Gemini om audio-overzichten te genereren ontstond het idee om de voorbeelden die ik daar gemaakt had ook apart te delen. Via een podcast. En […]