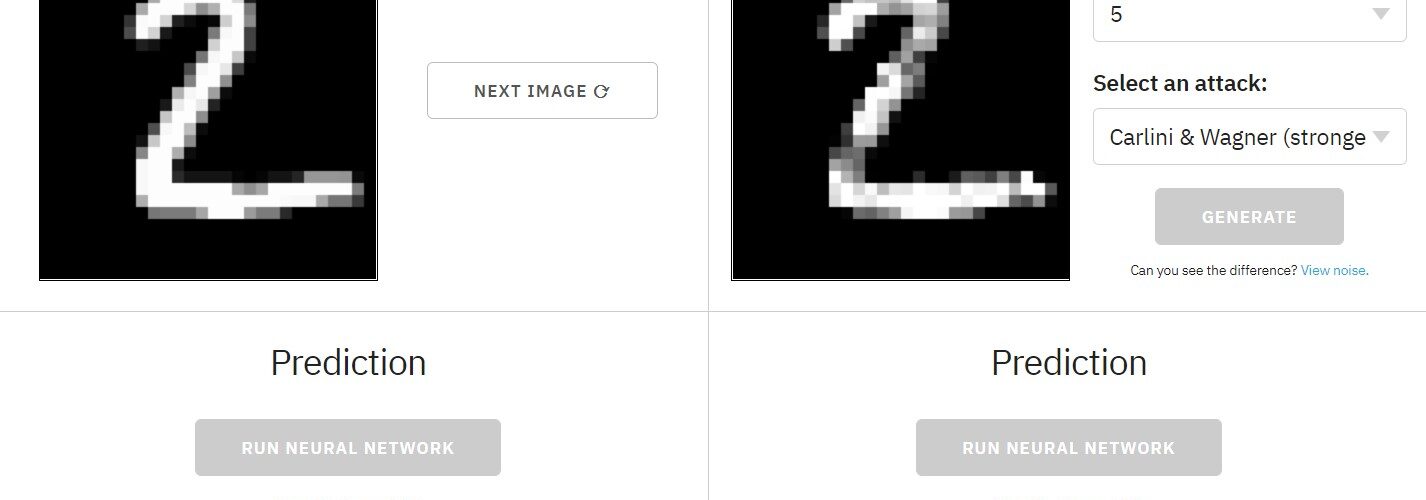

In de categorie “O Nee!”, maar ook wel “Ja, natuurlijk heeft iemand dat verzonnen” valt bovenstaande video. Daarin legt Kenny Song uit hoe je neurale netwerken kunt gebruiken om afbeeldingen dusdanig aan te passen zodat wij het verschil niet zien maar een ander neuraal netwerk volledig om de tuin geleid wordt. Je kunt de video bekijken, het zelf online uitproberen, een voorbeeld werkt waarschijnlijk het snelste.
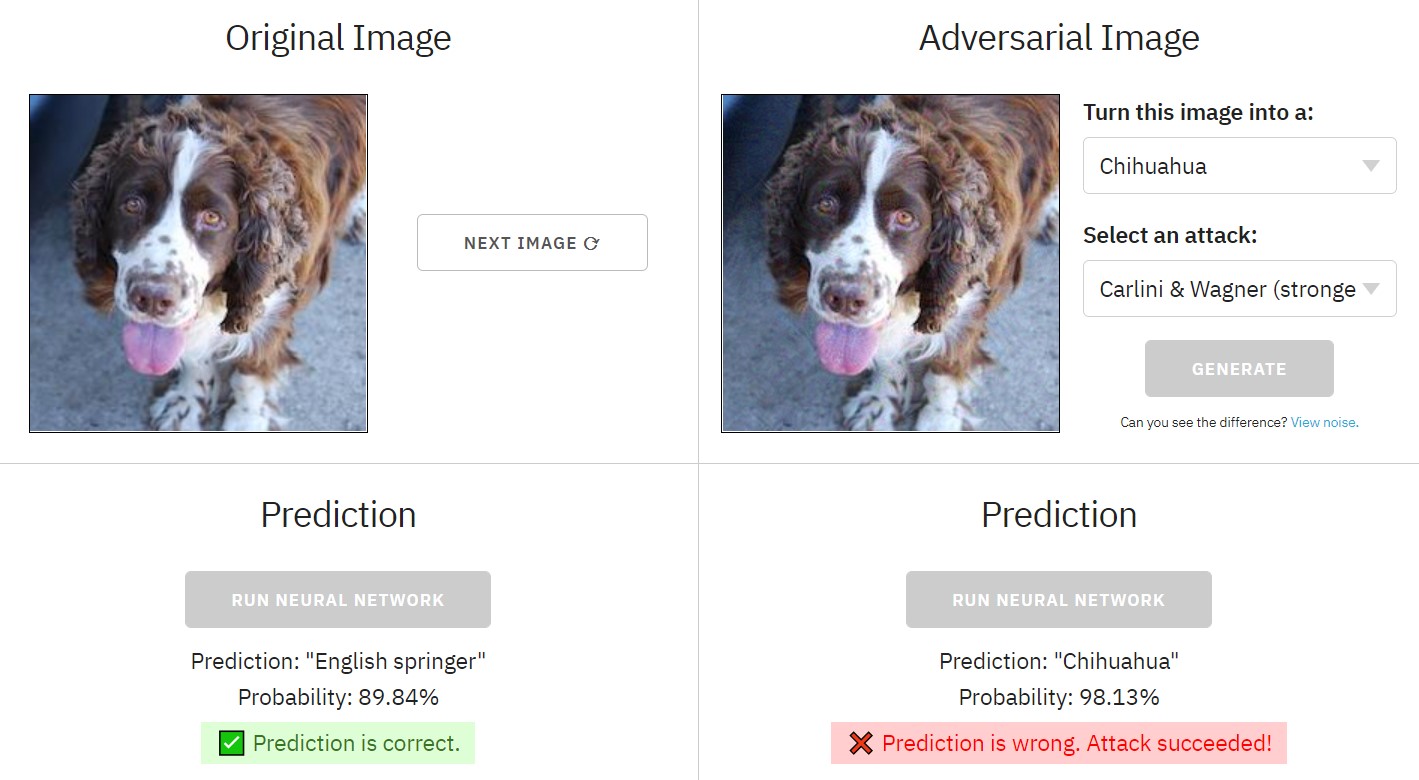
Links zie je een voorbeeld van een afbeelding uit de ImageNet bibliotheek. Normaal gesproken wordt die met 89,84% zekerheid herkend als een “English springer”. Rechts zie je dezelfde afbeelding die volgens een van de beschikbare methoden voor ons zo goed als onzichtbare ruis toegevoegd heeft gekregen (als je goed kijkt zie je dat deze wat vager is, andere varianten beperken het aantal pixels dat ze aanpassen maar passen elke pixel ingrijpender aan). Als je die afbeelding door hetzelfde neurale netwerk voert, dan komt er met 98,13% zekerheid de (gewenste/gekozen) classificatie van Chihuahua uit (Hotdog was een van de andere opties).
De website legt ook uit waarom dit meer is dan alleen grappig. Je zou dit namelijk ook doelbewust in kunnen zetten. Het voorbeeld waarbij je de herkenning van getallen kunt aanpassen zou je kunnen inzetten om zelfrijdende auto’s te misleiden door verkeersborden aan te passen. Dat hij bv denkt dat je ergens 90 km/uur mag in plaats van 30 km/uur. Wij als mensen zouden het verschil tussen die 9 of 3 dan niet of nauwelijks zien, wij zien gewoon een bord met 30 km/uur. Maar het machine learning algoritme in de auto ziet 90 km/uur en past de snelheid daarop aan.
Of het aanpassen van resultaten van gezichtsherkenning op Mission Impossible achtige manier, waarbij jij niet eens vermomd hoeft te zijn om door het systeem als iemand anders herkend te worden.
Natuurlijk is het doel van de website niet om doem en verderf af te kondigen. Het idee is dat je je machine learning algoritme traint voor dit soort aanvallen. Maar ook dat je het meeneemt in het ontwerp en ontwikkeling van je systeem: wat kan er mis gaan als iemand hier misbruik van maakt? Kun je bv 2 algoritmes naast elkaar laten draaien, of 3 zoals in een vliegtuig waarbij je verschillende voorspellingsmethoden gebruikt en kijkt of de resultaten overeen komen? (ik weet het niet, het zijn maar ideeën)
Cool is natuurlijk dat de voorbeelden op de website niet op een enorme supercomputer draaien, maar gewoon in je browser. Dat verklaart ook waarom sommige voorbeelden wat langer duren dan andere.



 AI-tools")