Ik had het er vandaag nog met een student over en toen ik daarna het bericht “I tested Gemini’s video analysis feature and the results were predictable” in mijn RSS-feed tegenkwam, vond ik het tijd om er toch even een bericht over te schrijven.
De titel (en ondertitel) zeggen het eigenlijk al: Onderzoek naar en vergelijkende tests van LLM’s zijn nutteloos als ze geen versienummers en modelnamen bevatten.
Het aantal modellen is simpelweg té groot, het verschil in capaciteiten tussen de modellen maakt gewoon enorm veel uit. Gewoon zeggen dat je “Gemini” gebruikt hebt zegt net zo min als stellen dat je ChatGPT gebruikt hebt.
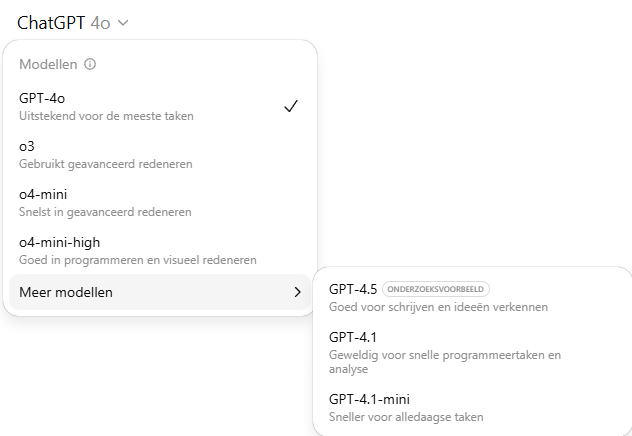
Op dit moment biedt de betaalde versie me 7 verschillende modellen via de chatinterface, met daarnaast nog de mogelijkheid om het model wel of niet op internet te laten zoeken of om juist diepgaand onderzoek uit te laten voeren.
Op gemini.google.com heb ik met een gratis account (op dit moment) de keuze uit Gemini 2.5 Flash en 2.5 Pro, op aistudio.google.com zie ik dan dat er ook varianten op die twee modellen zijn, klik ik daar door dan krijg ik deze lijst:

Eerder schreef ik al over het moordend tempo waarmee de grote bedrijven op dit moment modellen publiceren. Bij de open source taalmodellen is het nóg relevanter om te weten wat getest is. De claims zijn anders volstrekt belachelijk
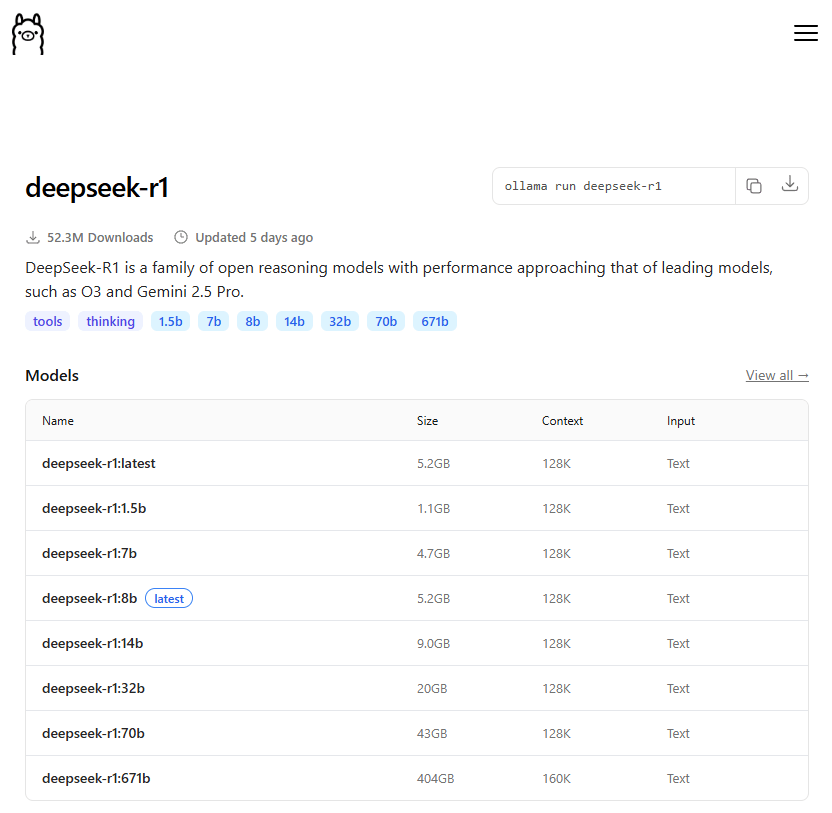
“a family of open reasoning models with performance approaching that of leading models, such as O3 and Gemini 2.5 Pro.” – wellicht als je het 671b model draait, maar met het 7b model haal je echt geen resultaten die vergelijkbaar zijn met Gemini 2.5 Pro. En als je modellen aan het testen, uitproberen of beoordelen bent (doen ze het “goed” of “niet goed”) dan kom je er niet onderuit om heel goed de omstandigheden waaronder je je tests doet te documenteren. Natuurlijk doen al die formele, officiële, technische tests dat wel, maar ook daar blijken nog wat kanttekeningen te plaatsen te zijn als het gaat om volledigheid en reproduceerbaarheid (zie bv McIntosh et al. 2025 hierover) . Maar ook al die bloggers, evangelisten, onderwijs onderzoekers, “experts” of iedereen met gebrek aan inspiratie die denkt “daar kan ik ook een bericht over schrijven”-mensen: zonder details is jullie bericht 0 komma niks waard. Dat het ook bij “serieus onderzoek” (peer reviewed wetenschappelijk onderzoek) voor kan komen blijkt wel uit Saleh et al. (2025). Die constateerden dat de hun onderzoek naar de efficiëntie, toepassingen en toekomstmogelijkheden van LLM’s op basis van hardware-eisen, trainingsmethoden, prestaties en praktische inzetbaarheid, gehinderd werd door gebrek aan volledigheid van de technische details in de 27 studies die ze bekeken hadden.

Referenties
- McIntosh, T. R., Susnjak, T., Arachchilage, N., Liu, T., Xu, D., Watters, P., & Halgamuge, M. N. (2025). Inadequacies of Large Language Model Benchmarks in the Era of Generative Artificial Intelligence. ArXiv. https://doi.org/10.48550/arXiv.2402.09880
- Saleh, Y., Abu Talib, M., Nasir, Q., & Dakalbab, F. (2025). Evaluating large language models: a systematic review of efficiency, applications, and future directions. Frontiers in Computer Science, 7. https://doi.org/10.3389/fcomp.2025.1523699



