Dit bericht valt onder de gebruikelijke categorie van “documenteren van dingen waar ik mee geëxperimenteerd hebt”. Laat ik beginnen met de constatering dat soms zaken heel snel gaan, andere zaken wat langer duren. Ruim 16 maanden geleden maakte ik deze video over RAG en Ollama, dat wat ik nu gedaan heb met n8n en de Ollama server van NOLAI is eigenlijk heel erg vergelijkbaar. Met een paar verschillen dan.
| Wat | Toen | Nu |
| Backend | Mijn eigen Ollama server, die op mijn desktop draaide. | Ollama bij NOLAI. |
| Coderen | Flowise en Python (Jupyter Notebooks) | N8N |
| Frontend | Browser | Signal |
Gebruik maken van de Ollama server bij NOLAI heeft als voordeel dat ik tóch gebruik kan maken van de open source taalmodellen die ik thuis ook zo draaien, maar dat die server 24 uur per dag, 7 dagen per week aan staat. Nadeel is dat ik daar geen beheerder ben, dus minder controle heb over wat er op de server kan.
De keuze voor N8N versus (toen) Flowise en Jupyter Notebooks is puur kwestie van smaak. In de onderlinge vergelijkingen komt N8N er uit als meer “klaar voor productie” dan Flowise. Maar of mijn workflows dat zijn is natuurlijk maar de vraag.
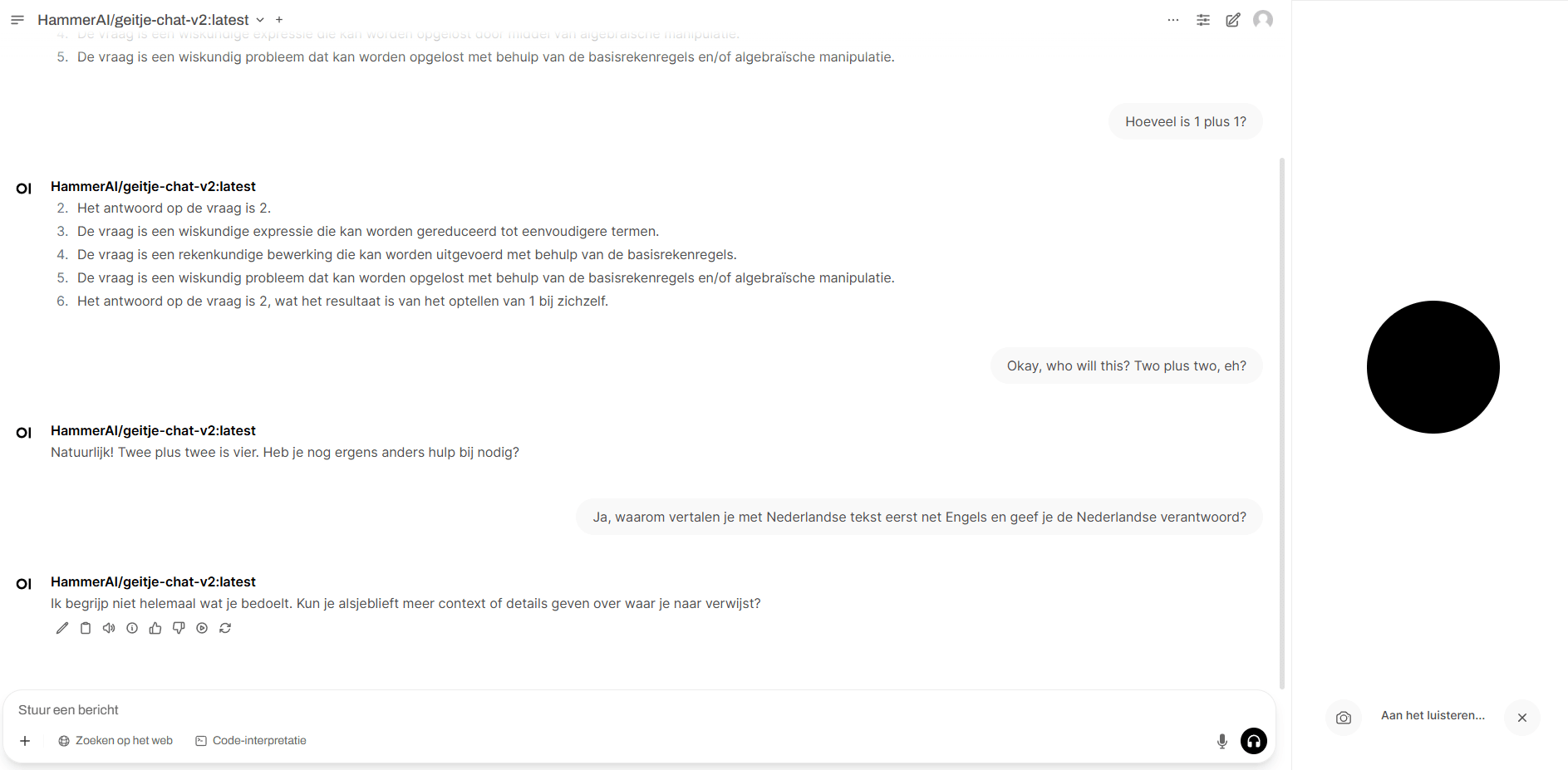
Vorig jaar had ik een chatvenster in de browser, zoals je in de video kunt zien vond ik het experimenteren met “waar kun je toegang geven tot de chatbot” heel relevant, want je wilt dat de chatbot daar beschikbaar is waar de gebruikers hem nodig hebben, niet dat de gebruikers persé naar één plek (een website in een browser) moeten gaan om met de chatbot te communiceren.
Het is verbazingwekkend hoe ingewikkeld het blijkt te zijn om zo’n chatbot te koppelen aan bijvoorbeeld WhatsApp of Signal. De meeste online voorbeelden veronderstellen voor WhatsApp dat je een bedrijfsaccount bij Meta aanmaakt. Anders moet je, zoals ik nu ook voor Signal gedaan hebben, zelf in staat zijn lokaal een servertje te draaien (in Docker) dat als een interface tussen je chatbot en respectievelijk WhatsApp of Signal werkt. Het resultaat voelt dan een beetje houtje-touwtje.
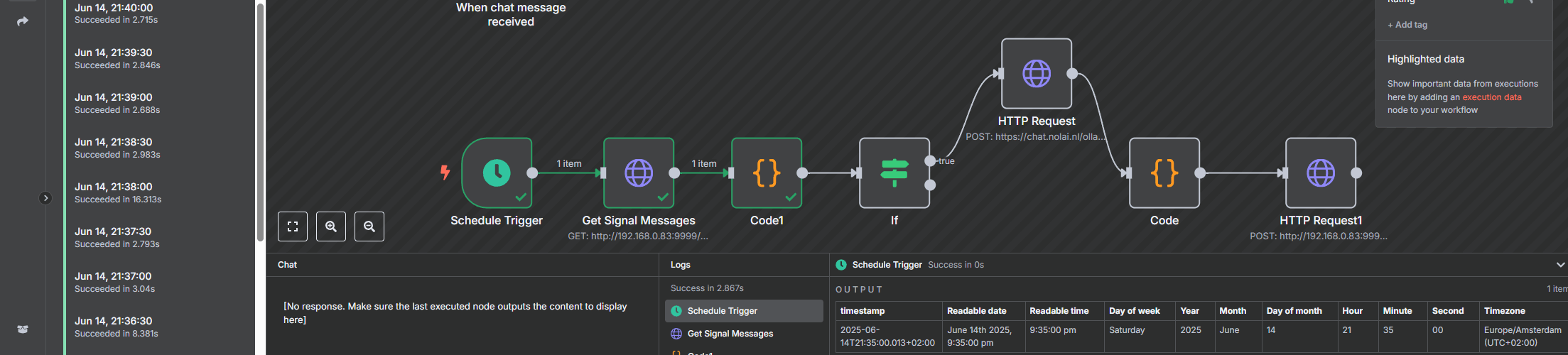
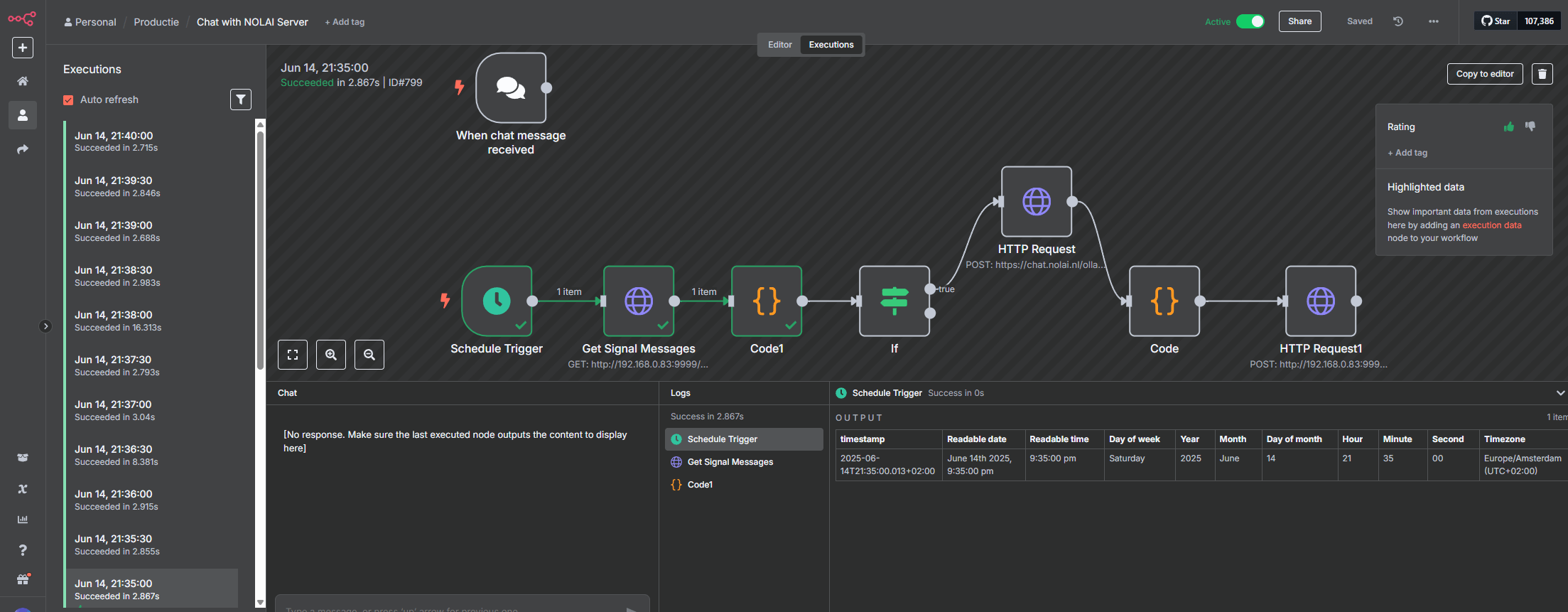
De workflow
De N8N-workflow staat online op github. De workflow kijkt elke 30 seconden op de Signal Messenger REST API server die ik heb draaien en aan mijn 06-nummer gekoppeld heb of er nieuwe berichten binnen gekomen zijn die starten met “@AI”. Als dat het geval is, dan wordt via een HTTP-request dat bericht als boodschap richting de NOLAI-server gestuurd via de API die daar beschikbaar is. Het antwoord dat terugkomt van de server wordt dan weer via de Signal Messenger REST API server teruggestuurd. Het is allemaal nog tamelijk basic. In theorie zou als iemand anders mij via Signal een bericht stuurt dat start met “@AI” de workflow ook moeten triggeren. Maar omdat ik als antwoord-06 nummer dat van mij nog hard in de code heb zitten, komen de antwoorden dan bij mij terecht. Denk ik tenminste. Als je het wilt testen, dan ga je gang, als er té flauwe zaken gevraagd worden (of eigenlijk als de antwoorden die ik dan krijg té flauw zijn) dan moet ik hem offline halen totdat ik aangepast heb dat de antwoorden ook weer naar de afzender retour gaan.
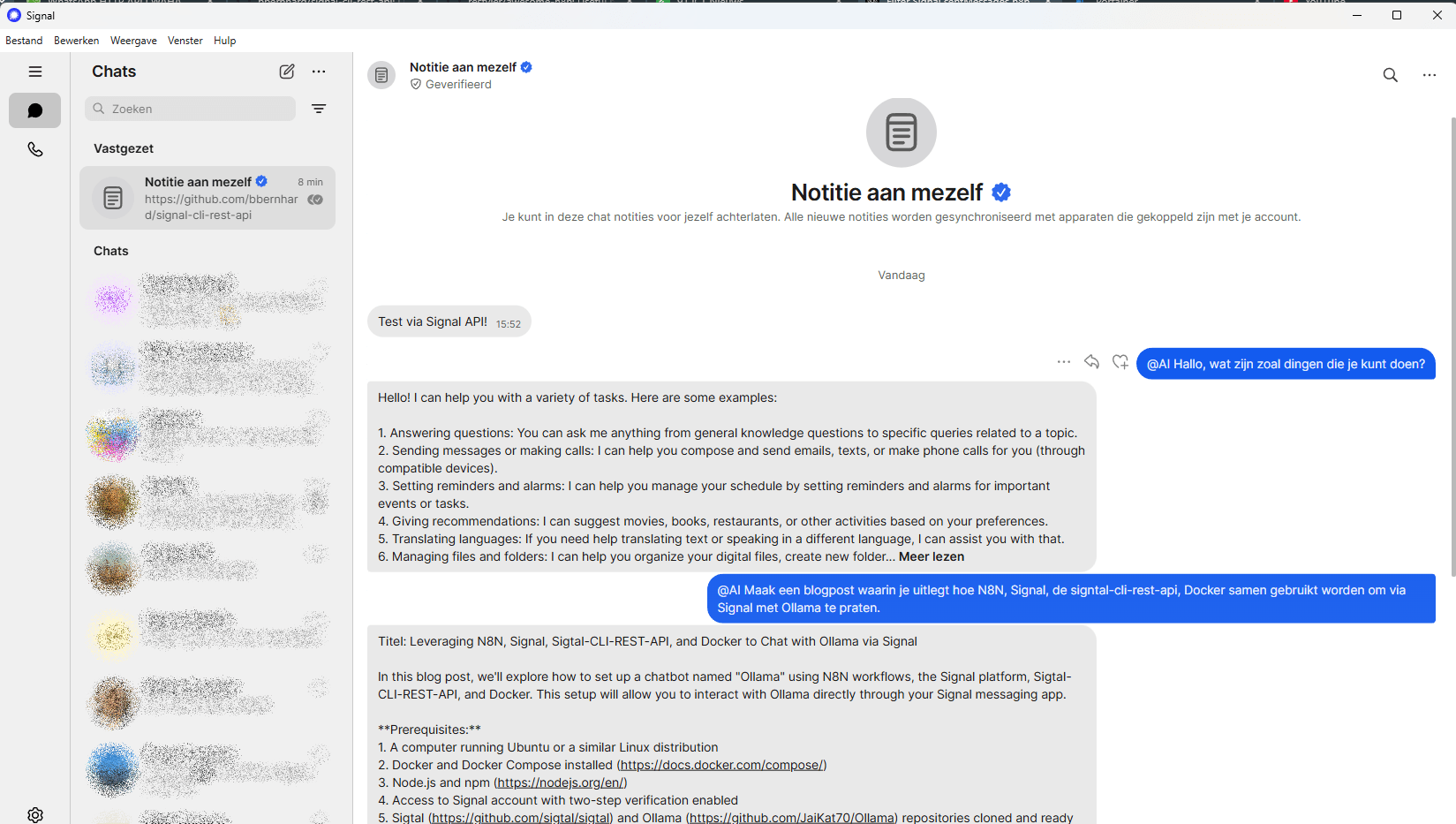
Als ik dan, net als dat standaard al in Open WebUI beschikbaar is, met de bot wil kunnen praten, vraagt ook dat weer het nodige uitzoekwerk. Conclusie blijft dus dat ook met een nocode of lowcode platform als N8N het in 2025 nog best veel werk blijft als je je eigen frontend voor een LLM wilt bouwen. Jammer, maar leerzaam, want als je de YouTubers zou geloven die er dagelijks filmpjes over maken, is het iets wat je zo in 5 minuten doet. Max.