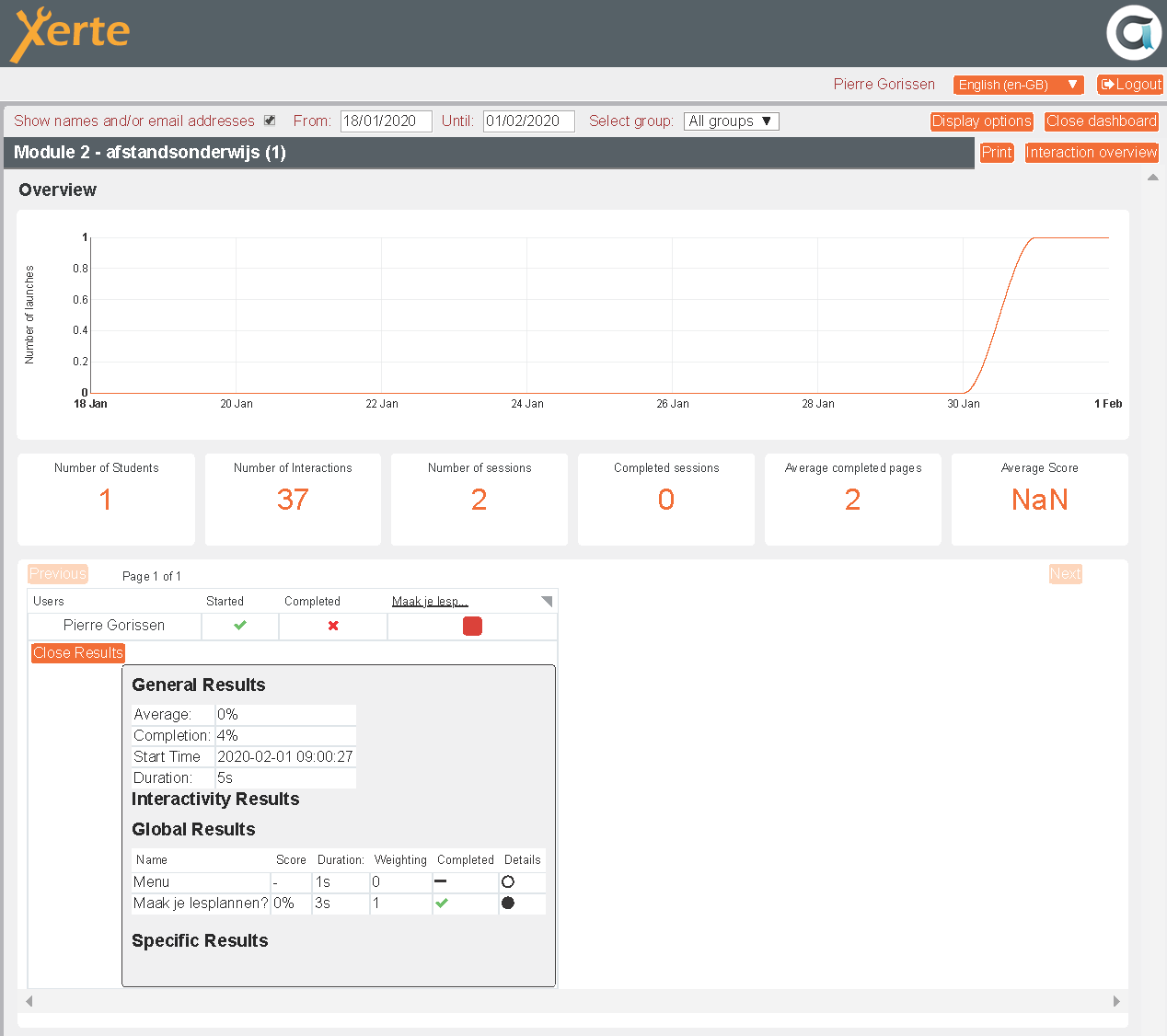
 Ruim een jaar geleden ging ik voor het eerst aan de slag met Learning Locker en Xerte (bericht 1 en bericht 2). Toen lukte het me niet om de combinatie aan de praat te krijgen.
Ruim een jaar geleden ging ik voor het eerst aan de slag met Learning Locker en Xerte (bericht 1 en bericht 2). Toen lukte het me niet om de combinatie aan de praat te krijgen.
Dat had met name te maken met het niet voor elkaar krijgen van link met Learning Locker, met SCORM Cloud ging het zonder problemen.
Dit jaar waren/zijn er een paar dingen anders dan vorig jaar:
- Ik heb nu een nieuwe Synology, een Diskstation DS918+ die niet alleen veel meer kracht heeft dan mijn vorige Synology, maar ook ondersteuning heeft voor Docker;
- Sinds vorig jaar heeft Xerte een aantal uitbreidingen gekregen op het gebied van Learning Analytics die interessant zijn om te bekijken;
- Binnen een van onze samenwerkingsverbanden gaan we van start met een pilot/demonstrator op dit gebied waarbij we gebruik gaan maken van de combinatie Learning Locker, Xerte en een leeromgeving met ondersteuning voor LTI.
Voor het project hoef ik niet zelf de technische zaken te regelen, dat doen anderen. Maar bij het denken over de vraag hoe we met learning analytics en dashboards docenten én studenten kunnen ondersteunen, helpt het mij als ik zelf met mijn vingers aan de knoppen kan zitten.
Dus daarom voldoende reden om te kijken of ik het geheel nu wél aan de praat kon krijgen.
Docker op Synology
Tot voor kort was mijn kennis van Docker beperkt tot het gebruik op mijn laptop (en dus onder Windows). Dat is toch anders, want zo’n laptop gebruik je voor veel verschillende dingen, gaat aan en weer uit (slaapstand). De Synology is een systeem met een INTEL Celeron J3455 processor op 1.5Ghz en 4 kernen. Mijn systeem heeft 16GB intern geheugen. Er draait dus een x86-64 bits Linux versie op. Dat is anders dan bv op een Raspberry Pi waarbij er een ARM processor aanwezig is.
De Synology heeft zelf een redelijk uitgeklede Linuxversie geïnstalleerd staan, maar doordat het systeem ondersteuning heeft voor Docker, kun je daar wat aan doen.
Hoe ik dat het beste kon doen, wist ik eerst ook nog niet.
 Ik heb heel veel gehad aan de playlist op YouTube die gemaakt is door “BeardedTinker“. Die gaat weliswaar over Home Assistant (heb ik wél op een Raspberry Pi draaien, maar nog niet binnen Docker), maar zijn werkwijze vormt de basis voor de manier waarop ik Docker nu op mijn Synology gebruik. Daarbij staan een paar dingen centraal:
Ik heb heel veel gehad aan de playlist op YouTube die gemaakt is door “BeardedTinker“. Die gaat weliswaar over Home Assistant (heb ik wél op een Raspberry Pi draaien, maar nog niet binnen Docker), maar zijn werkwijze vormt de basis voor de manier waarop ik Docker nu op mijn Synology gebruik. Daarbij staan een paar dingen centraal:
- Ik maak gebruik van een SSH-verbinding met de Synology voor het bouwen van images, het voor de eerste keer starten van nieuwe containers en voor het uitvoeren van docker-compose scripts.
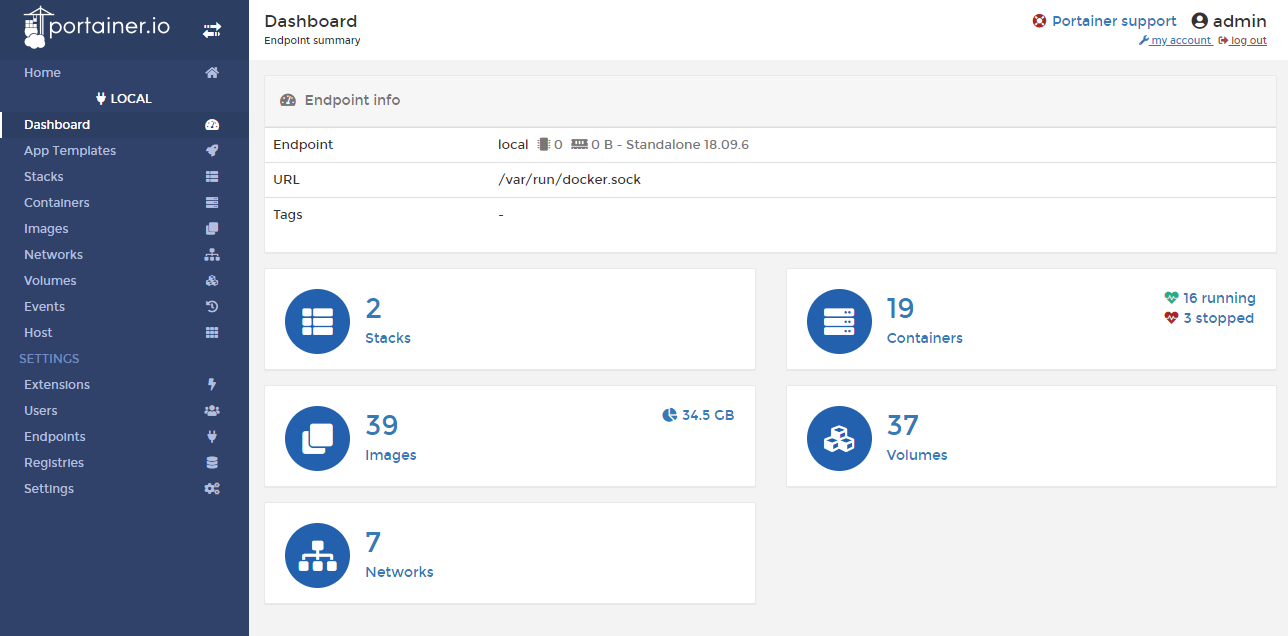
- Ik maak geen gebruik meer van de ingebouwde Synology interface voor het beheren van images en containers, in plaats daarvan gebruik ik Portainer (een Docker image voor het beheren van Docker images…). Ik vind het overzicht in Portainer fijner (overzichtelijker), maar dat kan persoonlijke voorkeur zijn.
- Ik gebruik mappen onder /volume1/docker/… voor de lokale bestanden per container. Die koppel ik dan via de -v (volume) parameter aan de betreffende container.
Installatie Portainer
Voor Portainer heb ik het volgende commando gebruikt (zoals te vinden onder deze video):
sudo docker run --name="portainer" -d --restart=always -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock -v /volume1/docker/portainer:/data -v /usr/syno/etc/certificate/system/default:/certs portainer/portainer
Daarvoor heb ik eerst een map /volume1/docker/portainer aangemaakt. Door daarna dit commando te runnen vanaf de SSH commando van de Synology wordt er een image gedownload (“portainer/portainer”) en een container (“portainer”) aangemaakt die op poort 9000 van mijn Synology beschikbaar is. Daarmee krijg ik toegang tot (op dit moment) 19 containers (16 draaiend, 3 gestopt) en 39 images (die dus niet allemaal gebruikt worden!) op mijn Synology.
Voordat ik met de uitleg over de installatie van de andere onderdelen verder ga, eerst even een poging om de structuur en samenhang duidelijk te maken.
Xerte / xAPI / LTI / LRS
Een tijdje geleden, in april 2018 alweer, gaf Tom Reijnders een update van de xAPI mogelijkheden in versie 3.6 van Xerte. Je kunt de video hieronder bekijken en hij is nog steeds relevant.
Hoe werkt dit nou?
Ik heb een poging gedaan om de werking van de verschillende onderdelen schematisch weer te geven:
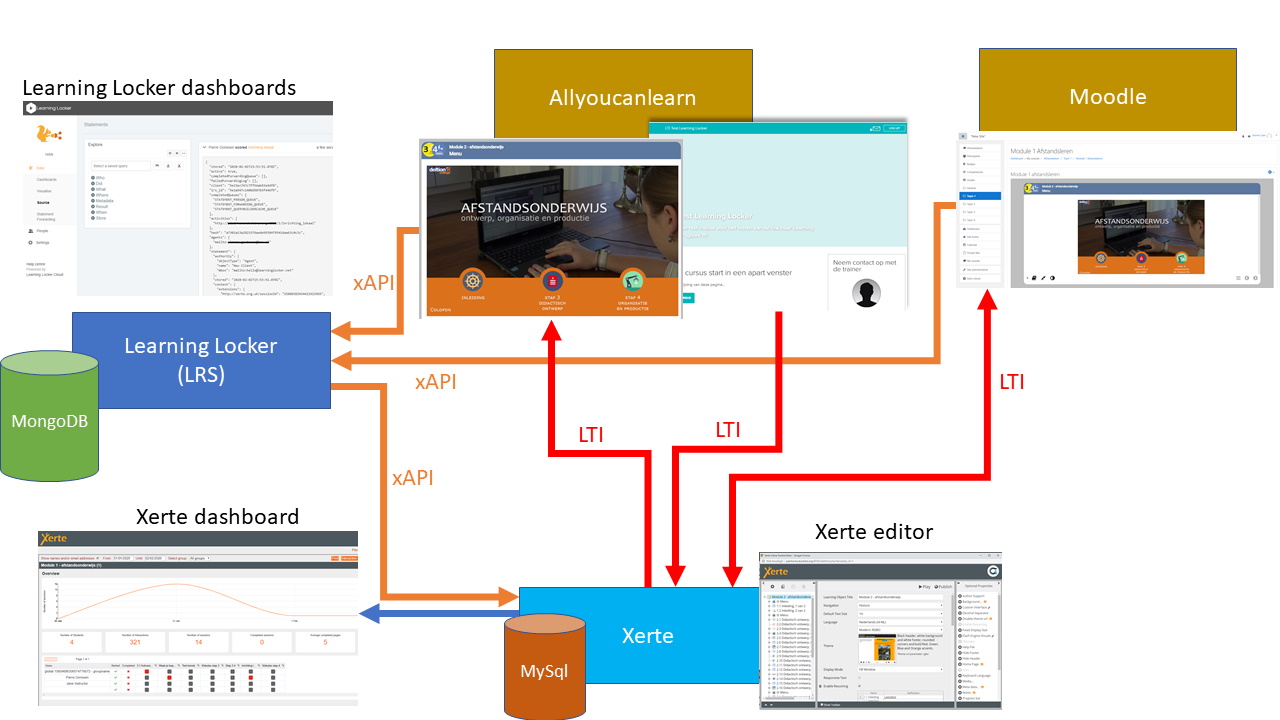
Je ziet in de afbeelding de verschillende onderdelen die ik geïnstalleerd heb en gekoppeld heb:
- Learning Locker, een open source Learning Record Store (LRS). Die heeft een aantal functies: ontvangen van data via de Experience API (xAPI) specificatie; het weer beschikbaar stellen van die data (ook via xAPI, bv aan Xerte), het maken en uitserveren van dashboards op basis van die data.
- Xerte, een open source auteursomgeving voor e-learning content. Xerte heeft niet alleen ondersteuning voor xAPI, maar ook (na installatie van Tsugi) voor de Learning Tools Interoperability (LTI) specificatie.
- Moodle, een open source leeromgeving met ondersteuning voor LTI.
Niet lokaal geïnstalleerd, maar wel gebruikt omdat het relevant was:
- Allyoucanlearn.eu, een open leerplatform binnen Zorg & Welzijn met eveneens ondersteuning voor LTI.
In stapjes:
Het begint allemaal in Xerte. Hier heb ik een module in geïmporteerd die ik bij het Deltion College gedownload heb
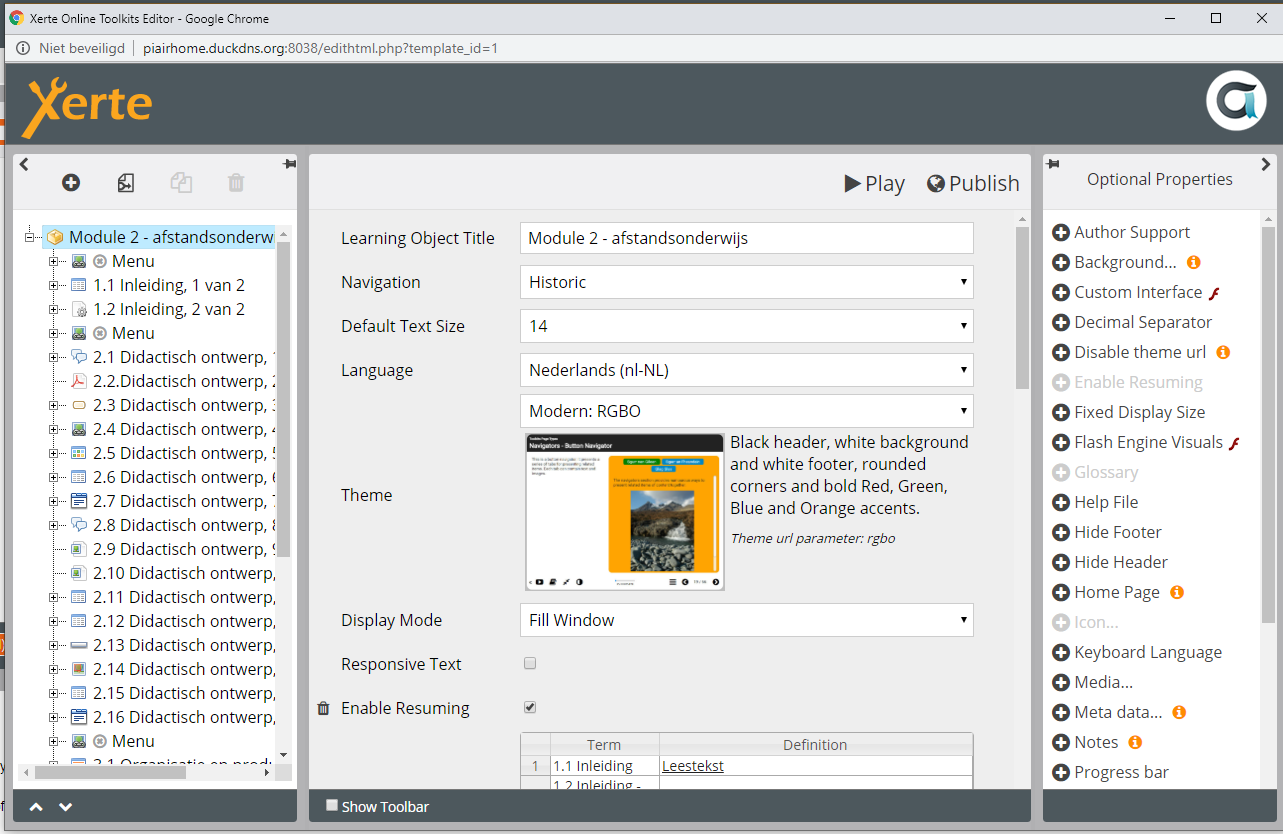
Die module kan ik bewerken, ik kan er onderdelen aan toevoegen, verwijderen, de tracking aanpassen etc.
Maar voor nu laat ik hem even zoals hij is. Ik hoef maar 2 dingen aan te passen in de properties van het project:
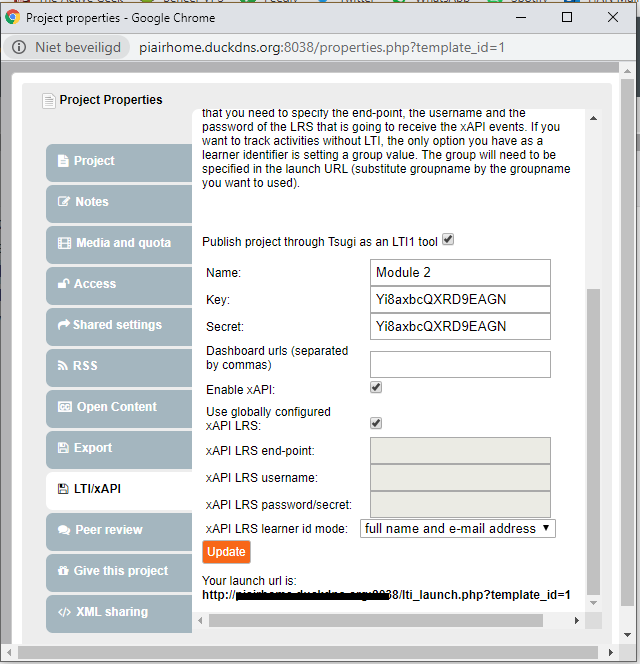 Ik moet de xAPI instellingen aanpassen (een xAPI LRS end-point, de xAPI LRS username en het xAPI LRS password/secret) zodat ze verwijzen naar de Learning Locker LRS (in dit geval).
Ik moet de xAPI instellingen aanpassen (een xAPI LRS end-point, de xAPI LRS username en het xAPI LRS password/secret) zodat ze verwijzen naar de Learning Locker LRS (in dit geval).
Ik moet de LTI Key en Secret instellen.
En uiteraard (tel ik even niet als stap 3): ik moet de vinkjes aanzetten bij “Publish project through Tsugi as an LTI1 tool” en bij “Enable xAPI”.
Als ik dan op “Update” klik, krijg ik een “launch url” te zien.
Hiermee heb ik 2 verschillende zaken ingesteld:
De xAPI info zorgt ervoor dat het leerobject in staat is de trackinginformatie naar de LRS te sturen. De leeromgeving (Moodle, Allyoucanlearn, Canvas, Natschool etc) weet daar helemaal niets van. Je kunt xAPI ook zónder LTI gebruiken, maar dan wordt alleen groepsinfo naar de LRS gestuurd, dan is je naam/mailadres niet bekend.
De LTI (launch url + Key + Secret) info wordt wél door de leeromgeving gebruikt. Daarmee wordt namelijk vanuit die leeromgeving het leerobject gestart. In dit geval vanuit Allyoucanlearn in een nieuw venster en in Moodle als onderdeel van de pagina/module.
Omdat het leerobject nu via LTI, vanuit de leeromgeving gestart wordt, is meer info over de deelnemer bekend (naam + mailadres). Die worden nu ook via xAPI naar de Learning Locker LRS gestuurd. Belangrijk verschil tussen LTI en SCORM: het leerobject blijft de hele tijd ín Xerte en gaat dus niet over naar Moodle of Allyoucanlearn. Voordeel daarvan is dat je op één centrale plek het leerobject kunt wijzigen. Nadeel is wel dat bij een populair leerobject de Xerte installatie op een omgeving moet staan die krachtig genoeg is voor het aantal gebruikers.
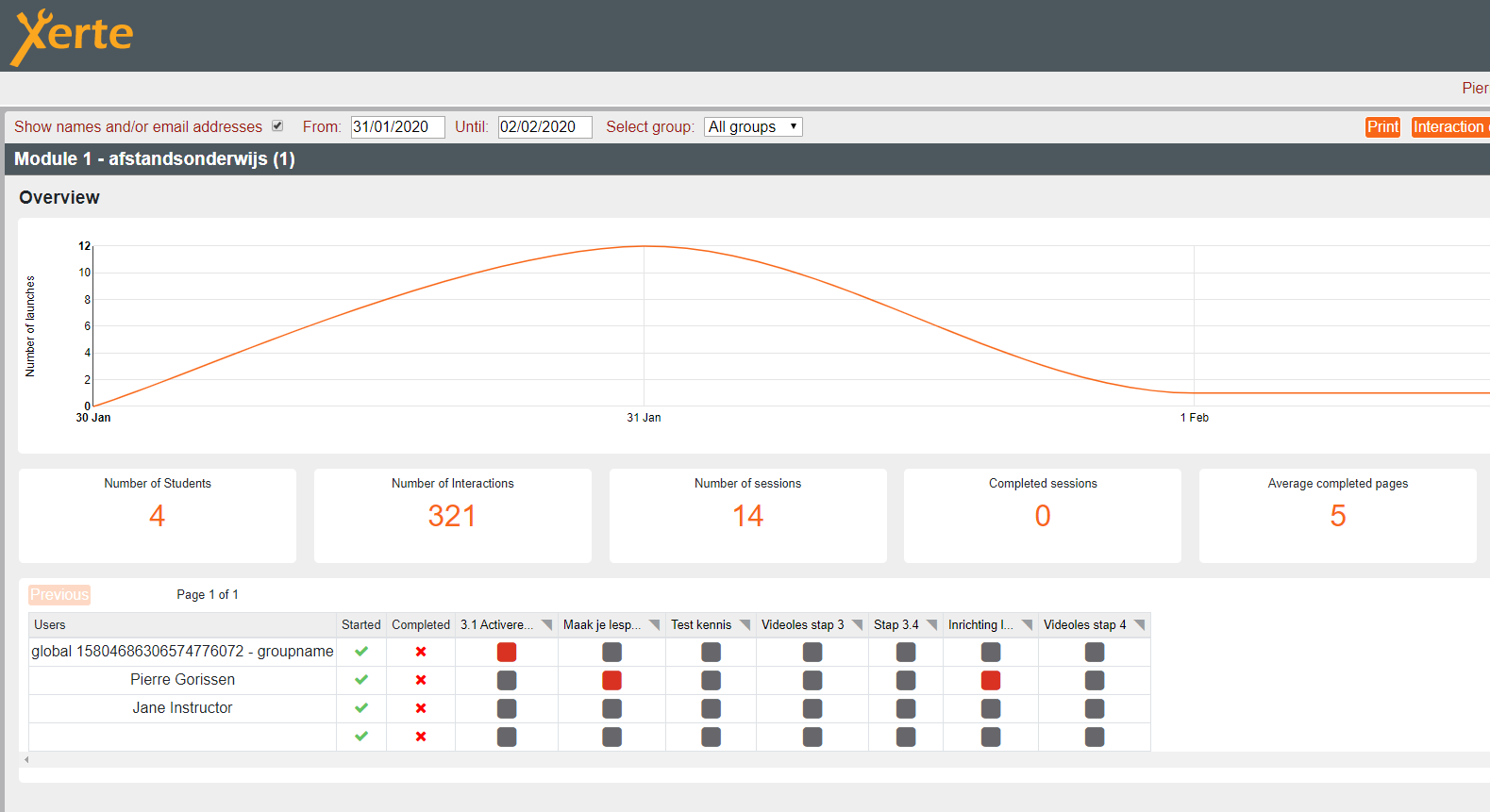
Xerte doet nog een extra ding: de omgeving gebruikt de ingevulde xAPI informatie bij een module om in de gekoppelde LRS ook weer de ontvangen data op te halen zodat ook in Xerte zelf een dashboard met gebruiksinformatie kan worden weergegeven.
En daarmee is het cirkeltje in de afbeelding rond.
Wélke informatie beschikbaar is, is afhankelijk van de instellingen in het leerobject. Geef je daar bijvoorbeeld het gekozen antwoord op een vraag door of alleen de score? Of een pagina of interactie “getrackd” wordt moet je daar instellen.
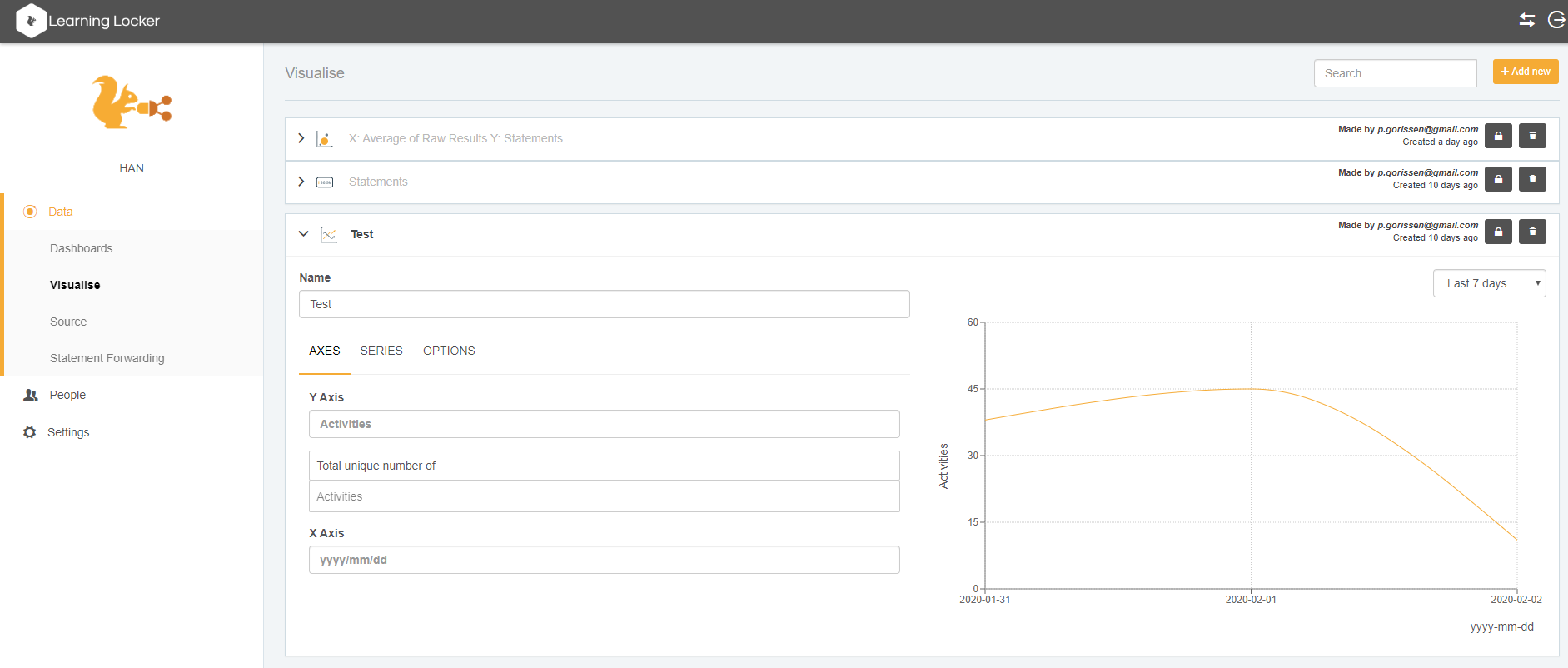
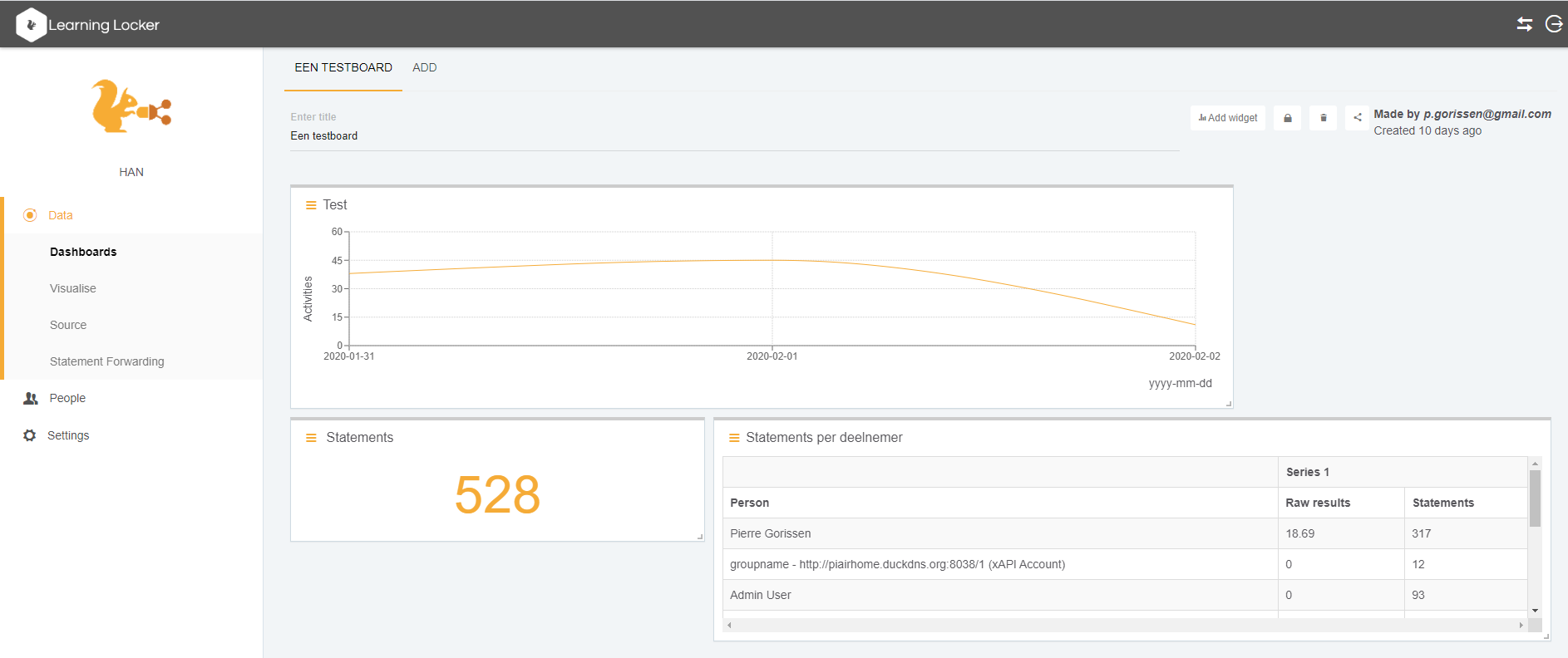
Welke informatie te zien is, ligt in Xerte helemaal vast, in Learning Locker kun je zelf “visualisaties” maken: grafieken / tabellen / overzichten op basis van alle beschikbare data. Die visualisaties kun je dan weer in Dashboards combineren. De dashboards zijn in Learning Locker zelf te bekijken, maar ook daarbuiten (als je dat wilt).
Tot zover
Voor mij helpt het om “met mijn vingers” aan zo’n omgeving te kunnen zitten bij het bevatten van de complexiteit en de relevante vraagstukken. In dit geval: welke data wil je allemaal opslaan vanuit het leerobject én welke visualisaties zijn handig/nuttig voor docenten en studenten (elk in hun eigen rol). En dan niet: leuke overzichten maken omdat de data er is en het kan, maar ze beperkt mogelijke overzichten maken die precies die info bevatten die nodig is (en bij voorkeur de mogelijkheid tot inzoomen bevatten als dat wenselijk is).
Ik verwacht eigenlijk nu al dat de conclusie straks gaat worden dat we niet al de benodigde dashboards kunnen maken. Ook al omdat we hier maar 1 databron hebben (de leerobjecten) en zo’n LRS juist gaat uitblinken als je er vanuit meerdere databronnen informatie naar toe stuurt (en die dan weer combineert), of als je neurale netwerken inzet om te helpen verbanden te vinden.
In een vervolgbericht kom ik nog even terug op de verschillende docker-statements die nodig waren om de hierboven gebruikte componenten aan de praat te krijgen.



 AI-tools")