 De sportschool is dicht, buiten fietsen is nog geen optie zolang mijn pols nog niet 100% hersteld is, binnen fietsen doe ik regelmatig maar dat leidt tot dagen dat ik helemaal niet buiten geweest ben. En dat is ook niet prettig. Dus gaan we ’s avonds regelmatig wandelen, met z’n tweeën soms ook met de kinderen erbij. Ik neem dan altijd mijn Garmin Forerunner 35 mee. Die heeft ingebouwde GPS en een “wandelen” modus. Die zet ik aan en dan hoef ik er het hele uur of iets meer dat we lopen niet meer aan te denken. Als we thuis komen zet ik hem op stop en binnen een minuut is de wandeling, via mijn telefoon, beschikbaar via Strava. Nou gaat het me niet echt om mijn hartslag of hoe hard we lopen (al vinden ook daar soms discussies over plaats), het gaat me ook niet om het kunnen opscheppen over het aantal wandelingen (op Strava volg ik allemaal mensen die verder, vaker fietsen, zwemmen, lopen, wandelen). We vinden het gewoon leuk om wat variatie aan te brengen in de routes die we wandelen, dus kwam ook wel de vraag op: “welke delen van het dorp hebben we nog niet gehad?”
De sportschool is dicht, buiten fietsen is nog geen optie zolang mijn pols nog niet 100% hersteld is, binnen fietsen doe ik regelmatig maar dat leidt tot dagen dat ik helemaal niet buiten geweest ben. En dat is ook niet prettig. Dus gaan we ’s avonds regelmatig wandelen, met z’n tweeën soms ook met de kinderen erbij. Ik neem dan altijd mijn Garmin Forerunner 35 mee. Die heeft ingebouwde GPS en een “wandelen” modus. Die zet ik aan en dan hoef ik er het hele uur of iets meer dat we lopen niet meer aan te denken. Als we thuis komen zet ik hem op stop en binnen een minuut is de wandeling, via mijn telefoon, beschikbaar via Strava. Nou gaat het me niet echt om mijn hartslag of hoe hard we lopen (al vinden ook daar soms discussies over plaats), het gaat me ook niet om het kunnen opscheppen over het aantal wandelingen (op Strava volg ik allemaal mensen die verder, vaker fietsen, zwemmen, lopen, wandelen). We vinden het gewoon leuk om wat variatie aan te brengen in de routes die we wandelen, dus kwam ook wel de vraag op: “welke delen van het dorp hebben we nog niet gehad?”
Iemand vroeg me onlangs naar voorbeelden van computational thinking. Nou dit is er eentje, hoewel het inderdaad eentje is waarbij een stukje programmeren gedaan is (deel twee van de vraag was namelijk of dat betekende dat er altijd programmeren bij kwam kijken). Het is een probleem/vraag die ik met ict opgelost heb.
De vraag herformuleren
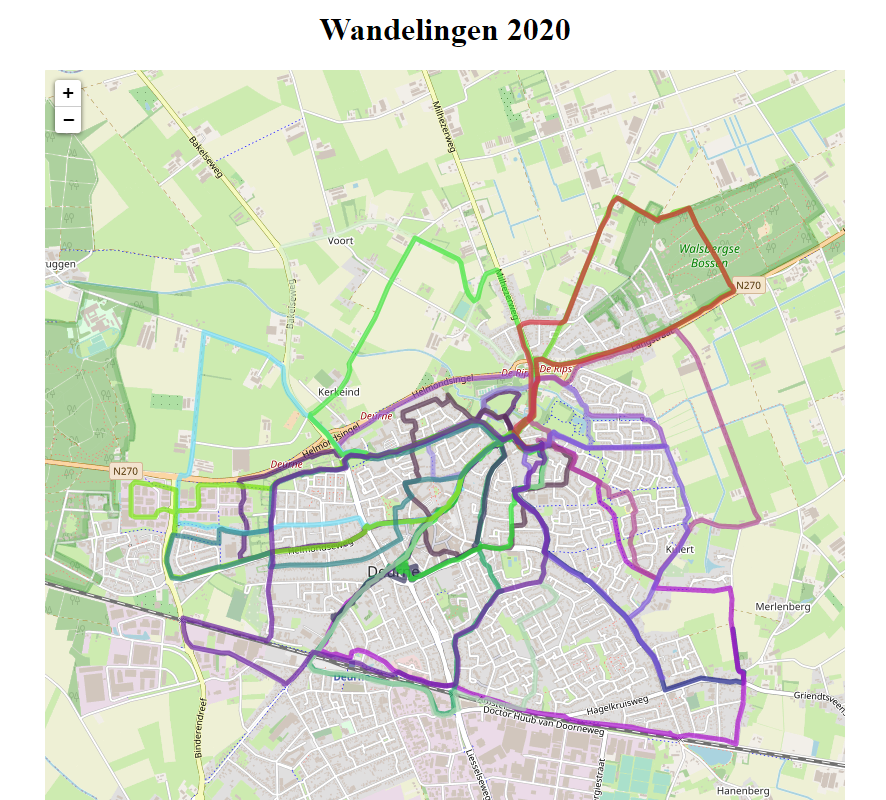
De vraag “welke delen van het dorp hebben we nog niet gehad?” is niet zomaar te beantwoorden. Omdat ik “alle” wandelingen die ik gemaakt heb (ik denk dat ik er een of twee gemist heb) opgenomen heb, zijn die beschikbaar op Strava. Dus ik kan wel de vraag beantwoorden “welke routes in het dorp hebben we wél gehad?”.
Strava kan die kaarten laten zien. Maar alleen pér wandeling. Niet als totaaloverzicht.
Onderzoeken van mogelijke oplossingen
Gelukkig heeft Strava wel een API, een interface waarmee je data uit je eigen account kunt opvragen. En dan kun je zelf de routes op een kaart tekenen (zoals ik hierboven gedaan heb). Zoals bij bijna alles: als ik het kan verzinnen, heeft iemand anders het vast ook al eens verzonnen. Op Youtube staat een serie video’s van Fran Polignano die eerst een introductie geeft op het gebruik van de API (heel handig om eerst te bekijken!), daarna uitlegt hoe je de API in Python gebruikt en daarna met JavaScript. Bij die laatste gaat hij dan nog even door en legt uit hoe je je activiteiten automatisch op kunt laten halen én allemaal tegelijkertijd op een kaart kunt laten zien. Daarbij is hij dan ook nog eens zo vriendelijk om zijn code te delen via Github.
Nou schreef ik hierboven “mogelijke oplossingen”. En dat is bewust. Want hoewel het plaatje hierboven al doet vermoeden dat ik dé oplossing voor elkaar heb, is dat niet helemaal het geval. De oplossing van Fran bevat in de JavaScript-code namelijk dit stukje:

Daar waar nu allemaal ‘xxxx’ staan moet je je eigen client-id, secret en refresh-token invullen. En dat is nogal onveilig. Want als ik die HTML-pagina hier gewoon op mijn website zou zetten, dan zou iedereen met een klein beetje verstand van HTML en Javascript in staat zijn die gegevens uit mijn pagina op te vragen. En dan hebben ze blijvend toegang tot mijn Strava account via de API (tenzij ik de app die ik bij Strava aangemaakt heb verwijder, een nieuw client-secret genereer, maar dan werkt mijn eigen pagina ook niet meer totdat ik de code daar weer toevoeg).
Nu maakt dat niet uit omdat ik de HTML-pagina lokaal kan openen en dan gewoon een screenshot van de kaart maak, maar het is nog niet optimaal. Het is een prototype. Ik wilde eerst kijken of ik hiermee de gewenste functionaliteit kon realiseren.
Uitbreiden van het origineel
Gebruik maken van het werk van iemand anders heeft niet als doel om dan maar gewoon snel klaar te zijn. Het maakt het mogelijk om te kijken hoe je die code kunt uitbreiden zodat de gegeven oplossing beter aansluit bij wat je zelf wilde bereiken.
Dus heb ik een Fork gemaakt van de repository van Fran zodat ik de code kon downloaden, bewerken en weer online kon delen. De wijzigingen zitten in één bestand: strava_api.js
Wat heb ik gewijzigd?
Selectie van alleen wandelingen
Omdat ik ook mijn trainingen op de Tacx in de serre opsla op Strava, staan er redelijk wat activiteiten op die niet met wandelen te maken hebben (en ook geen route omdat ik binnen fiets). Ik heb een extra check toegevoegd if (data[x].type == "Walk") die kijkt of de activiteit een wandeling is voordat hij op de kaart gezet wordt.
Detailroute ipv samenvatting
Fran gebruikte alleen de “samenvatting” van de routes op de kaart. Bij Strava kun je aangeven dat er een soort privacy-zone om je woonlocatie gehanteerd wordt. Al start jij zodra je de voordeur uitloopt en stop je zodra je weer terug naar binnen loopt, de op de kaart getoonde route wordt niet tot aan de voordeur getoond.
Voor deze verzamelkaart vond ik dat wat minder een probleem. Sowieso deel ik alleen de afbeelding, inzoomen op huis wordt dan moeilijk. Ja, je kunt absoluut uit de afbeelding afleiden waar ik (ongeveer) woon. Dat vond ik nu niet zo’n probleem.
Maar de detailroute is alleen beschikbaar als je de info van een specifieke activiteit opvraagt, de samenvatting krijg je al meteen als je bv de laatste 60 activiteiten van jouw account opvraagt.
Dus heb ik een tweede loop toegevoegd die steeds voor elke wandeling de detailroute opvraagt en die toevoegt aan de kaart.
Willekeurige kleuren per route
Standaard hadden alle routes dezelfde kleur via color:"green", met de eenvoudige aanpassing color: "#" + Math.floor(Math.random()*16777215).toString(16) wordt er voor elke route een willekeurige andere kleur gekozen. Niet elke combinatie ziet er dan even mooi uit, maar een keer refreshen helpt dan.
Inzoomen op de routes
De code van Fran vereiste dat je zelf ongeveer wist wat het midden van alle routes was (en dat handmatig invulde) + bijbehorend zoomniveau.
met var polyline = L.Polyline.fromEncoded(data.map.polyline); latlngbounds.extend(polyline.getBounds()); en map.fitBounds(latlngbounds); doet het script dat automatisch voor je.
Samenvattend
Dit eerste prototype doet functioneel wat het moet doen, maar vergt nog een stevige aanpassing voor wat betreft de beveiliging. Sowieso zorgt hij er nu voor dat bij elke keer herladen van de pagina, de data opnieuw bij Strava opgehaald wordt. Strava stelt limieten voor de aantal keer dat je dat per 15 minuten mag doen en geeft je anders een foutmelding (en dan moet je even wachten). Heel logisch ook, want steeds die data ophalen is onnodig, die zou ik lokaal (of op mijn eigen server) moeten cachen.
Dat betekent dat een oplossing die volledig gebaseerd is op JavaScript, niet zo handig is, een stukje code in Python op de server die de gegevens bevat voor het inloggen en die de data daar cached, gecombineerd met JavaScript die de kaart zelf tekent zou dan beter werken. Is iets voor de volgende versie.
Wanneer die gereed is? Dat weet ik niet precies. Dat is het nadeel van een prototype dat voor nu goed genoeg werkt. 😉
Computational Thinking
Voor wat betreft die link naar Computational Thinking: zoals je ziet volgde ik niet een-op-een de stappen zoals je ze bij bv SLO wel ziet, maar je ziet er bijna allemaal toch in terug: Ik heb het probleem geherformuleerd zodat ik het beter kon oplossen, daar heb ik ook abstractie bij toegepast: het is niet noodzakelijk precies aan te geven waar ik nog niet gewandeld heb, door te laten zien waar ik wél gewandeld heb, krijg ik een goed genoeg beeld. Gegevens verzamelen was niet het verzamelen van nieuwe gegevens, maar het verzamelen van gegevens die ergens anders (Strava) al opgeslagen waren. Gegevens analyseren bestond uit het logische ordenen van de gegevens (de gelopen routes) en visualiseren van de gegevens op een kaart zodat ik aan de hand daarvan kon zien wat het antwoord op de vraag was. Om de data op te halen moest ik het probleem opknippen (probleem decompositie): eerst de algemene data bij Strava ophalen, daarna de detaildata. Het stukje automatisering van het oplossen van het probleem spreekt voor zich. Het algoritme voor het oplossen van het probleem is te vinden in de JavaScript code. De parallelisatie is waarschijnlijk moeilijker te begrijpen omdat je die niet direct in de code terugziet (als je niet weet hoe dat werkt). De JavaScript code stuurt namelijk kort achter elkaar verzoeken naar Strava voor de detailinfo van de wandelingen. Nog voordat het antwoord vanaf de server voor de ene binnen is gekomen gaat de code al verder en op het moment dat de dan binnen komt wordt die ook op de kaart gezet.
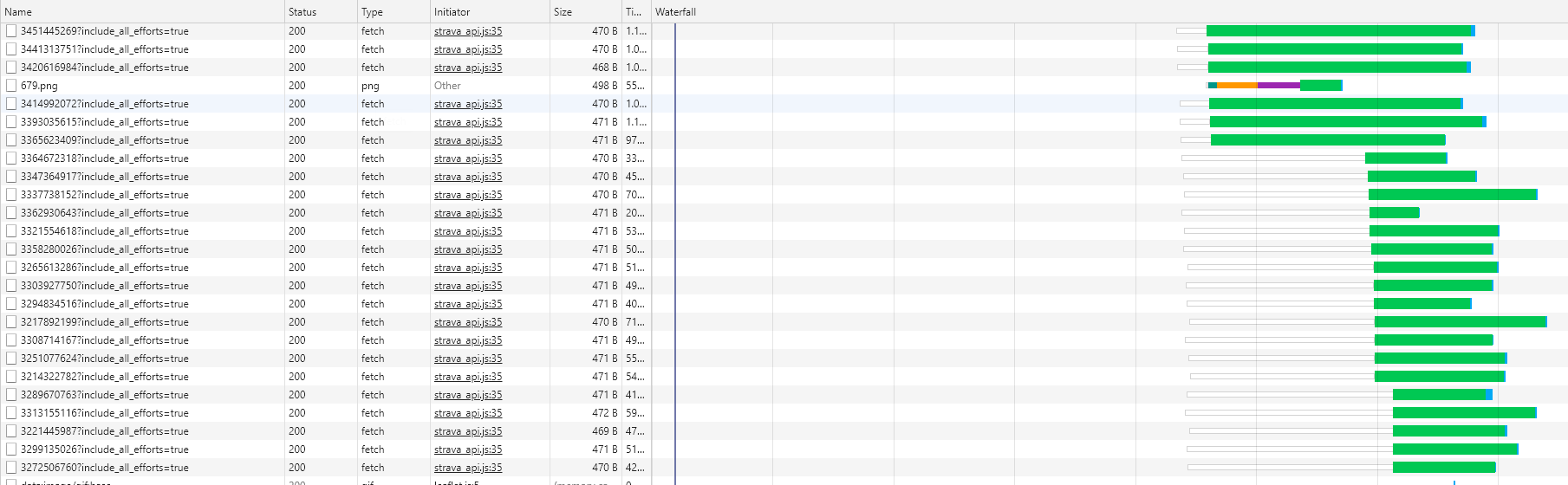
Wellicht dat bovenstaand plaatje het wat duidelijker maakt. Dit is uit de ontwikkelaarsweergave van Chrome (als je er op klikt, krijg je een grotere versie te zien). Elke regel is het opvragen van de details van een wandeling, daarnaast zie je een tijdlijn, de start van het balkje is het moment dat de browser de data opvraagt, groen is de start -> stop van de binnenkomst van de data. De browser vraagt ze bijna allemaal tegelijkertijd op, het doorlopen van de loop in JavaScript gaat heel snel omdat hij niet wacht op het antwoord, de code is zo opgebouwd dat op het moment dát de data binnenkomt, deze verwerkt wordt.
Een stap die niet persé bij Computational Thinking hoort (is veel generieker) is natuurlijk dat ik mijn stappen, keuzes, resultaten documenteer en deel met anderen.



