 Learning Locker, de LRS die we gebruiken voor de pilot/demonstrator binnen Allyoucanlearn (zie ook deze aantekeningen) heeft ingebouwde mogelijkheden voor het bouwen van dashboards. Tot nu toe heb ik daar niet zo’n heel goede ervaringen mee. Het maken van overzichten die zouden kunnen dienen als voorbeelden voor gebruik tijdens gesprekken met docenten en studenten als het gaat om hun behoeften aan informatie, wil nog niet echt vlotten.
Learning Locker, de LRS die we gebruiken voor de pilot/demonstrator binnen Allyoucanlearn (zie ook deze aantekeningen) heeft ingebouwde mogelijkheden voor het bouwen van dashboards. Tot nu toe heb ik daar niet zo’n heel goede ervaringen mee. Het maken van overzichten die zouden kunnen dienen als voorbeelden voor gebruik tijdens gesprekken met docenten en studenten als het gaat om hun behoeften aan informatie, wil nog niet echt vlotten.
Bij de Veracity LRS heb je binnen de omgeving tamelijk uitgebreide rapportagemogelijkheden (zie deze demonstratie) maar die mogelijkheid is alleen aanwezig in de online versie, niet in de gratis downloadbare versie. Hoewel de video tamelijk chaotisch is, beschikt die over iets dat “aggregation pipeline” heeft als onderdeel van de omgeving waarmee de widgets voor het dashboard maakt. En zover ik kan overzien is dat bij Learning Locker niet aanwezig. Daarom ging de zoektocht in eerste instantie verder naar andere (generieke) dashboard tools om te bekijken of die ook geschikt zijn.
Een van de tools die daarbij naar voren kwam is Redash. Net als veel van zulke tools (en Learning Locker) heeft Redash een betaalde, online, versie van de dienst en een open source versie die je zelf kunt downloaden en installeren. Een sterk punt van Redash is het grote aantal databronnen waar de omgeving verbinding mee kan maken. Ik had een Sqllite database waarvan ik de dashboard resultaten niet kan delen, maar de omgeving kan we mee overweg, net als met Google Sheets, SQL Server, MySQL, MongoDB, InfluxDB om er maar een paar te noemen. Hoewel Learning Locker zelf gebruik maakt MongoDB was de keuze in dit geval om niet rechtstreeks een verbinding op te zetten, maar via de JSON interface van Learning Locker. Daarmee komt de werkwijze namelijk overeen met een situatie waarbij het dashboard ook ergens anders kan worden gehost.
Installatie van Redash
Op de Redash-website staat uitleg over het installeren van Redash met behulp van Docker. Die werkte voor mij niet helemaal, uiteindelijk had ik maar twee bestanden nodig: docker-compose.yml en .env. Als je de twee links volgt dan kun je de inhoud van de bestanden bekijken, je hebt ze beide nodig in een map, in mijn geval /volume1/docker/redash. Voor de wachtwoorden kun je gebruik maken van deze website (zet de wachtwoordsterkte op 32). Zoals in die bestanden is aangegeven had ik ook een /volume1/docker/redash/postgres-data en een/volume1/docker/redash/data aangemaakt. Daarna was het een kwestie van het uitvoeren van een viertal commando’s:
export COMPOSE_PROJECT_NAME=redash
export COMPOSE_FILE=/volume1/docker/redash/docker-compose.yml
sudo docker-compose run --rm server create_db
sudo docker-compose up -d
En de Redash server draaide met dank aan 7 aangemaakte containers:

De server heeft een aantal introductiestappen waarbij je je eerste dashboard aanmaakt.
Redash koppelen aan Learning Locker
Als je Redash koppelt aan een SQlite database dan heb je bij het opbouwen van de queries de beschikking over de nodige informatie die je helpt bij het opbouwen van een selectie. De tabellen en velden binnen die tabellen worden gegeven, bij het typen van de selecties kun je er voor kiezen om die automatisch aan te laten vullen en het inspringen van het resulterende statement kan netjes worden ingesprongen.
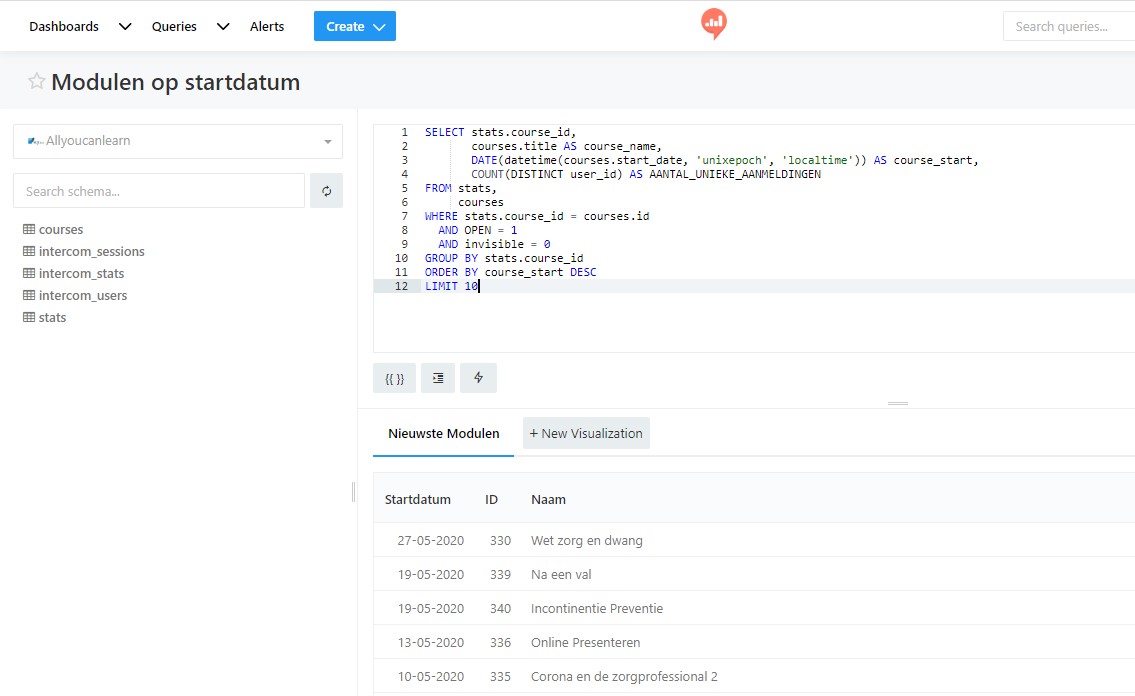
Bij een JSON-bron, zoals in dit geval Learning Locker heb je dat allemaal niet ter beschikking. Het is de bedoeling dat je zelf de URL samenstelt op basis waarvan er een JSON statement retour gegeven wordt. Bij het definiëren van de databron geef je (alleen) de gebruikersnaam en het te gebruiken wachtwoord op. Daarbij kun je bij het opvragen de nodige aanvullende parameters opnemen (zie ook deze help-pagina). Dat ziet er dan bijvoorbeeld zo uit:
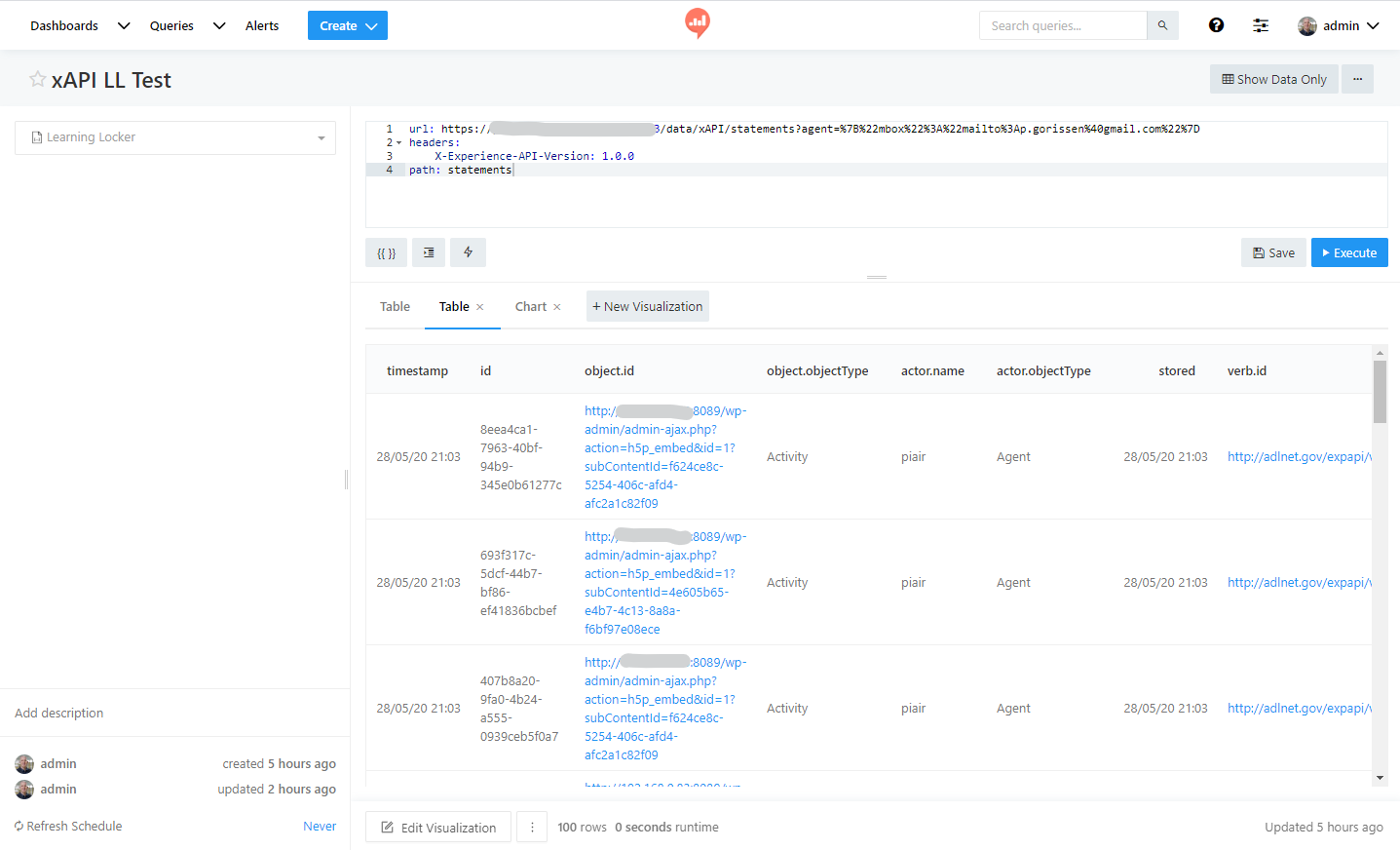
Dit is één manier om de xAPI statements op te vragen, Learning Locker beschikt daarnaast over een Aggregation HTTP Interface. Zoals ze zelf zeggen in het filmpje op die pagina, hebben ze die API toegevoegd omdat ze bij gebruik uitsluitend xAPI te maken kregen met grote hoeveelheden data die dan weer aan de kan van bv het Dashboard verwerkt moesten worden. Met die aggregation interface kun je dan zogeheten “pipelines” opzetten op basis van de Mongo aggregation API (MongoDB is dat database die onder Learning Locker hangt, dus het is logisch dat ze daar deze werkwijze voor gekozen hebben). Dat ziet er dan bijvoorbeeld zo uit:

Deze pipeline bestaat uit 4 onderdelen die je van boven naar onder moet lezen:
#1 In regel 2 t/m 6 wordt een eerste selectie (match) uitgevoerd: alleen statement met result.score.raw er in worden doorgegeven, we willen dus alleen statements met informatie over de scores voor bv een quiz.
#2 In regel 9 t/m 12 wordt een tweede selectie uitgevoerd: van de statements uit het eerste onderdeel wil ik alleen die hebben waarbij een mailadres van de deelnemer beschikbaar is (in de test Learning Locker installatie was dat niet altijd het geval bijvoorbeeld omdat een H5P video vanuit WordPress gestart was zonder ingelogde gebruiker, deze statements wil ik negeren)
#3 In regel 16 t/m 36 wordt dan een groepering uitgevoerd: per actor en daarbinnen per object wordt de gemiddelde score, de maximale score, de minimale score en de laatste score berekend op basis van de ruwe score die opgenomen is in het statement.
#4 In regel 39 t/m 43 wordt dan nog een laatste selectie uitgevoerd waarbij alleen de statements worden doorgegeven waarvan de berekende “last_score” waarde een waarde van >= 0 heeft. Deze selectie zou in dit geval overbodig moeten zijn vanwege de eerste filter, maar laat zien dat je ook op berekende waarden kunt selecteren/filteren.
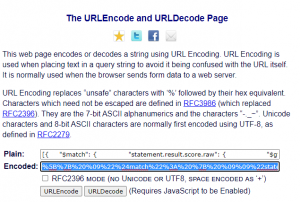 Zoals je wellicht gezien hebt, is zo’n aggregation statement op zichzelf ook weer een JSON-statement, maar om dat door te kunnen geven in een URL, moet je deze eerst “URLencoden”. Dit proces zet alle tekens die voor een browser verwarrend zouden kunnen zijn om naar zogeheten escape code (“%” gevolgd door de hexadecimale waarde van het teken). Zo word { dan bijvoorbeeld %123 en } wordt %125.
Zoals je wellicht gezien hebt, is zo’n aggregation statement op zichzelf ook weer een JSON-statement, maar om dat door te kunnen geven in een URL, moet je deze eerst “URLencoden”. Dit proces zet alle tekens die voor een browser verwarrend zouden kunnen zijn om naar zogeheten escape code (“%” gevolgd door de hexadecimale waarde van het teken). Zo word { dan bijvoorbeeld %123 en } wordt %125.
Het converteren van zo’n string hoef je gelukkig niet met de hand te doen, elke programmeertaal heeft wel een functie waarmee je dat kunt doen, ik heb voor het testen van de resultaten gebruik gemaakt van de urlencode/decode pagina die je hier kunt vinden. Daarbij is het een kwestie van het selecteren en kopiëren van het hele statement in de editor, plakken in het “Plain” vlak en een druk op de “URLEncode” knop.
Het resultaat is een tamelijk onleesbare brei:
%5B%7B%20%09%22%24match%22%3A%20%7B%20%09%09%22statement.result.score.raw%22%3A%20%7B%20%09%09%09%22%24gte%22%3A%200%20%09%09%7D%20%09%7D%20%7D%2C%20%7B%20%09%22%24match%22%3A%20%7B%20%09%09%22statement.actor.mbox%22%3A%20%7B%20%09%09%09%22%24exists%22%3A%20true%20%09%09%7D%20%09%7D%20%7D%2C%20%7B%20%09%22%24group%22%3A%20%7B%20%09%09%22_id%22%3A%20%7B%20%09%09%09%22actor_mbox%22%3A%20%22%24statement.actor.mbox%22%2C%20%20%20%20%20%20%20%20%20%20%20%20%20%22object_id%22%3A%20%22%24statement.object.id%22%20%09%09%7D%2C%20%20%20%20%20%20%20%20%20%22actor_mail%22%3A%20%7B%20%20%20%20%20%20%20%20%20%20%20%20%20%22%24first%22%20%3A%20%22%24statement.actor.mbox%22%20%20%20%20%20%20%20%20%20%7D%2C%20%09%09%22avg_score%22%3A%20%7B%20%09%09%09%22%24avg%22%3A%20%22%24statement.result.score.raw%22%20%09%09%7D%2C%20%09%09%22max_score%22%3A%20%7B%20%09%09%09%22%24max%22%3A%20%22%24statement.result.score.raw%22%20%09%09%7D%2C%20%09%09%22min_score%22%3A%20%7B%20%09%09%09%22%24min%22%3A%20%22%24statement.result.score.raw%22%20%09%09%7D%2C%20%09%09%22last_score%22%3A%20%7B%20%09%09%09%22%24last%22%3A%20%22%24statement.result.score.raw%22%20%09%09%7D%20%09%7D%20%7D%2C%20%7B%20%09%22%24match%22%3A%20%7B%20%09%09%22last_score%22%3A%20%7B%20%09%09%09%22%24gte%22%3A%200%20%09%09%7D%20%09%7D%20%7D%5D
Maar als je de brei hierboven zou selecteren, kopiëren en zou plakken in Encoded op die webpagina, den zou een druk op de URLDecode knop weer het oorspronkelijke JSON statement (weliswaar dan als één lange string met spaties) moeten opleveren.
Om in Redash een antwoord te krijgen in de vorm van een resultaat moet je er nog de url van je Redash installatie + wat extra parameters voor plakken:
https://jouwredashurl.com/api/statements/aggregate?cache=false&maxTimeMS=5000&maxScan=10000&pipeline=
Achter het pipepine= plak je dan de brei van hierboven. Als je een query bouwt binnen de databron waar je de Learning Locker gebruikersnaam en wachtwoord hebt ingevuld, dan krijg je zoiets:
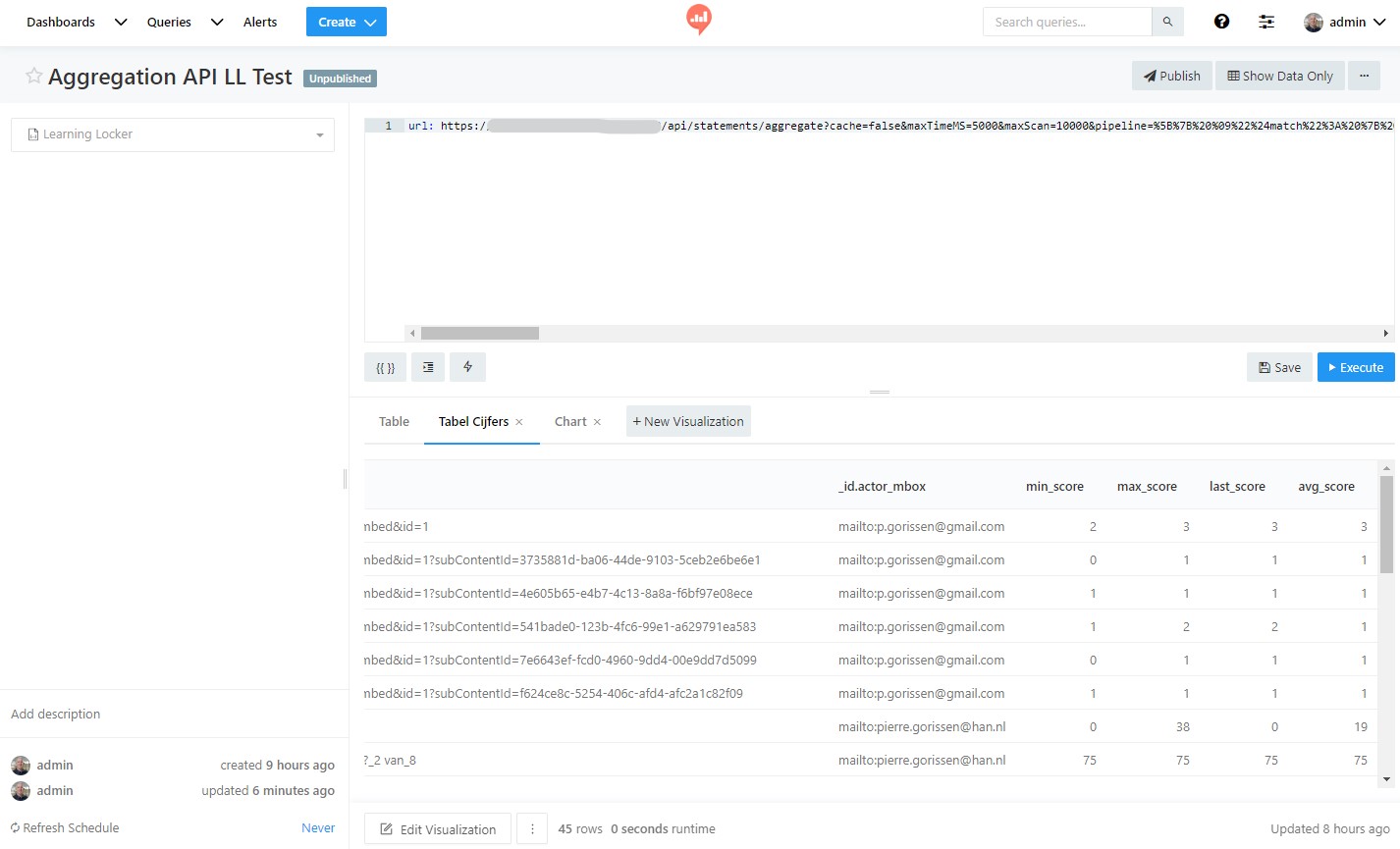
Je kunt hier weer visualisaties aan koppelen, maar ook dan is het nog niet zo intuïtief als gehoopt.

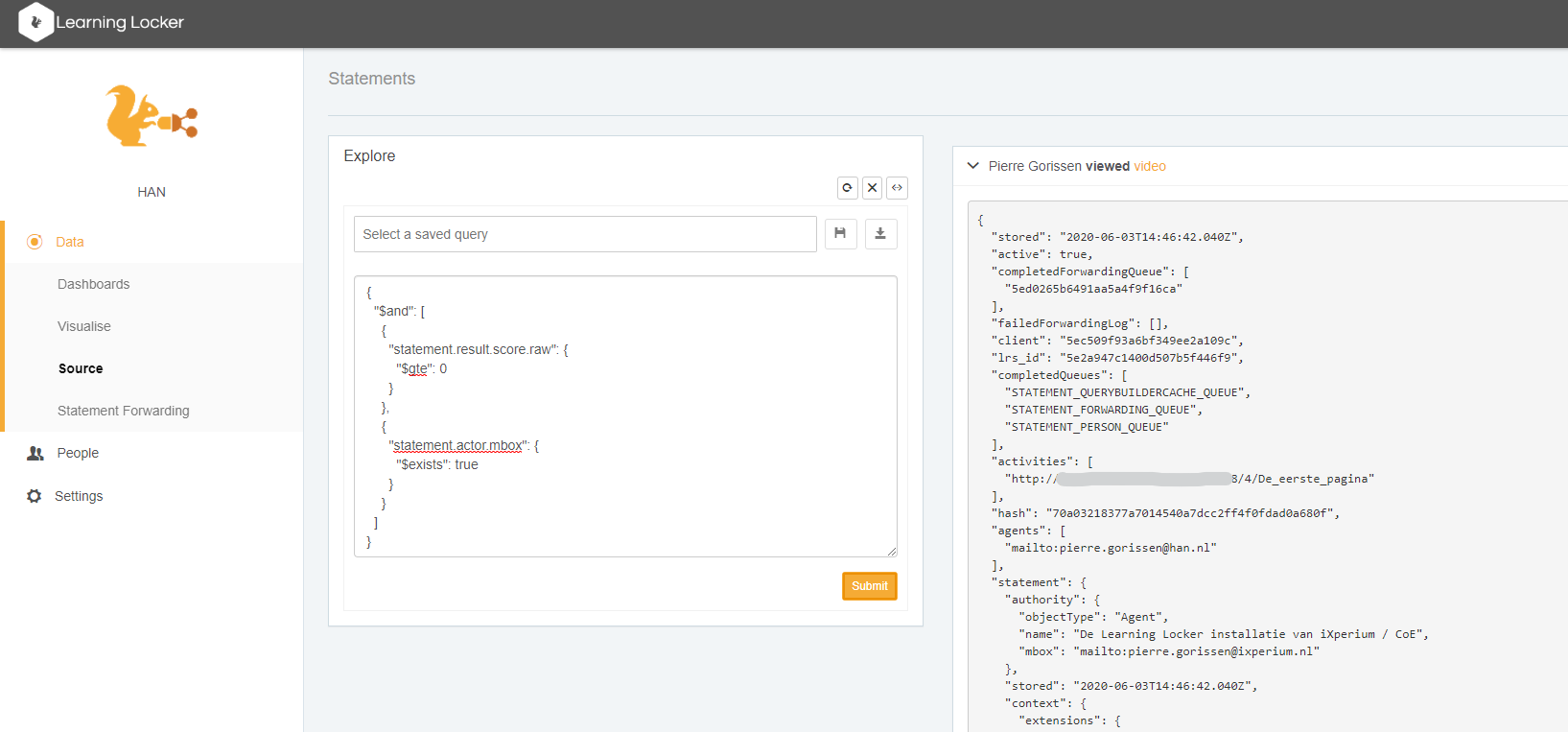
En natuurlijk heb ik nog even uitgeprobeerd of deze aggregation API ook binnen Learning Locker zelf beschikbaar is. Maar helaas: het statement levert “no items” op als ik hem rechtstreeks als query toevoeg. Het lijkt erop dat ik hier in ieder geval geen ketting van statements kan maken, een aantal selecties lukt wel, als ik de statements herschrijf naar bv
Conclusie
Het is even de vraag of verder experimenten met Redash zinvol is. Ja, het is mogelijk om de data via JSON binnen te krijgen. Maar de mate waarin het dan mogelijk is daar snel zinvolle dashboards mee te maken lijkt in dit geval beperkt. Daarnaast zie ik ook geen eenvoudige mogelijkheid om dashboards aan elkaar te koppelen zodat je als student of docent bijvoorbeeld eenvoudig op een overzichtsgrafiek kunt klikken (stel: voortgang van alle modules waar je mee bezig bent) om dan in te zoomen op de informatie van alleen die ene module.
Kortom, zeker geen plug-and-play optie voor wat we willen bereiken: eenvoudig aanpasbare voorbeeld-dashboards om het gesprek met docenten en studenten mee aan te gaan.


 AI-tools")
