 Hoewel ik vorige week al een blogpost geschreven heb voor zeven van de tien MOOCs van de Data Science specialisatie geschreven had, wilde ik er vandaag nog eentje toevoegen voor nummer 8: Statistical Inference.
Hoewel ik vorige week al een blogpost geschreven heb voor zeven van de tien MOOCs van de Data Science specialisatie geschreven had, wilde ik er vandaag nog eentje toevoegen voor nummer 8: Statistical Inference.
Het is namelijk, samen met Regression Models een van de twee struikel-MOOCs binnen de specialisatie. De redenen ervoor zoals te lezen op de fora verschillen. Ik weet dat ik hem de eerste keer dat hij uitgevoerd werd (gelukkig!) over geslagen heb. Toen bestonden de quizzes veelal uit open vragen en bleken er heel wat problemen met de software die de juiste antwoorden automatisch moest vaststellen. Er waren blijkbaar regelmatig correcte antwoorden die ten onrechte fout gerekend werden. Fataal natuurlijk als je maar 3 kansen hebt per quiz. Nou werden (zo kon ik meelezen) er wel extra kansen toegevoegd, maar dat wil je écht niet.
Daar komt bij dat deze MOOC gegeven wordt door Brian Caffo en in tegenstelling tot Jeff Leek en Roger Peng zeker geen natural als het gaat om via video’s laagdrempelig uitleg geven over statistiek. En dan gaat het om de hele combo: hij praat veel minder levendig en energiek dan de andere twee, de opbouw van zijn uitleg is warrig, vaak voegt hij niet veel toe aan wat er op de dia staat, worden grote stappen gemaakt, kortom, het zijn moeilijk te volgen video’s.
Van de andere kant, de MOOC heeft twee sterke punten wat mij betreft. Ten eerste heeft deze als enige van de 9 MOOCs geen project(en) en dus ook geen peer-review. Dat kwam voor mij nou goed uit omdat ik deze maand niet alle vier de weken thuis ben en nu klem zou komen zitten met de week dat ik het werk van anderen zou moeten reviewen. Daarom kan ik de Regression Models MOOC deze maand niet doen.
Een tweede voordeel wat mij betreft waren de huiswerk opdrachten.

Voor elke week waren er uitgebreide opdrachten die voorzien waren van uitleg. Ik heb ze allemaal gemaakt. Maar dan ook niet alleen online. Ik heb steeds een screenshot genomen van de vraag, die in een Word-document geplakt en daarna eronder de uitwerking. Dat is veel werk, maar het hielp heel erg bij het maken van de quizzes want sommige opdrachten daar herkende ik qua structuur van de huiswerkopdrachten en dan kon ik de uitwerkingen van daar aanpassen aan de getallen van de vraag bij de quiz en klaar.
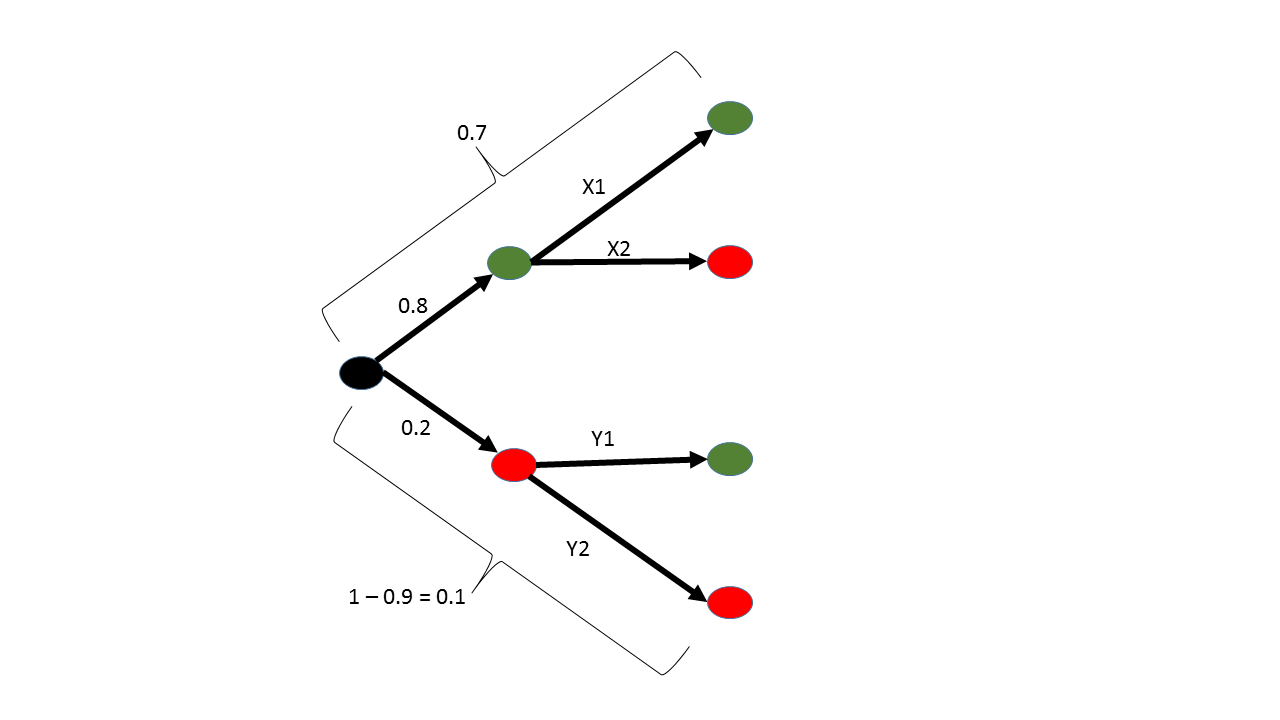
Overigens, ook de vragen van de quiz zelf heb ik op die manier aangepakt. Zie de afbeelding hierboven voor een van de vragen in de quiz. Waarom? Omdat na die 4 weken de MOOC afgesloten wordt, leeg gemaakt en opnieuw gestart. En aan de video’s + dia’s/PDF’s alleen heb ik niet zo heel veel. En de uitwerkingen van het huiswerk + de quizzes zouden nog wél eens van pas kunnen komen bij het afsluitende project.
Ik ben wel heel benieuwd naar de statistieken áchter deze MOOC. Want als er één MOOC in deze serie is die er voor kan zorgen dat mensen afhaken, dan is het deze wel. Ik zou het me niet kunnen voorstellen dat ik op dit punt in de specialisatie nog af zou haken, maar ik heb wel 2 volle dagen door moeten werken om de 4 quizzes (foutloos) te kunnen maken. En dat moet je dan wel op kunnen brengen.



