Vooraf: dit is geen klaagpost of afgeven op een leverancier. Dit is het documenteren van een constatering.
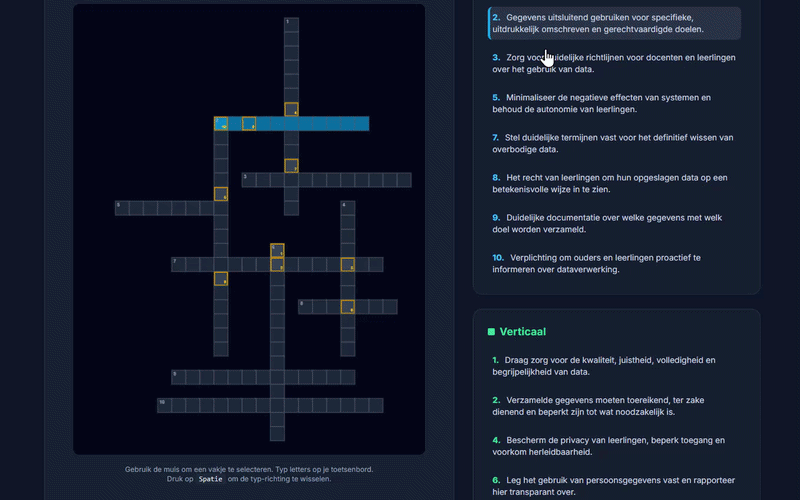
Gisteren was ik mijn college over Learning Analytics, ethiek en de AVG voor de HAN Master Ontwerpen van eigentijds leren (MOVEL) aan het voorbereiden. Ik zag een paar van de dia’s van vorig jaar en dacht “veel te veel tekst”. Maar ja, het waren allemaal begrippen waarvan het relevant was dat de studenten er in ieder geval een keer van gehoord hadden. Maar, zo dacht ik, daar moeten toch andere manieren voor zijn. Wat als ik een kruiswoordpuzzel maak waarbij de omschrijvingen de aanwijzingen zijn, de woorden ingevuld moeten worden en dan een nieuw woord ontstaat. Moet toch een fluitje van een cent zijn tegenwoordig met AI?
Nou…dat bleek nog tegen te vallen. Toen ik de (omvangrijke) prompt in Claude.ai met Sonnet 4.6 (adaptive) gooide, ging hij aan de slag, maar niet alleen zag het eerste resultaat er niet heel mooi uit, het klopte ook niet.

De woorden zorgden ervoor dat er letters naast elkaar kwamen die op zichzelf dan weer geen woord vormde. En dat mag niet. Verzoek om aan te passen leidde in eerste instantie tot het overschrijden van het aantal tokens dat ik met mijn €23,- per maand account per periode van 5 uur mocht gebruiken. Die waren niet allemaal hieraan opgegaan, maar goed, 2 uur wachten en dan verder. Maar ook bij de tweede poging kwam Claude er niet uit. Sterker nog: in 15 minuten joeg de omgeving door het tokenlimiet van de op dat moment net gestarte nieuwe 5 uur en toen sloeg de interface weer dicht.
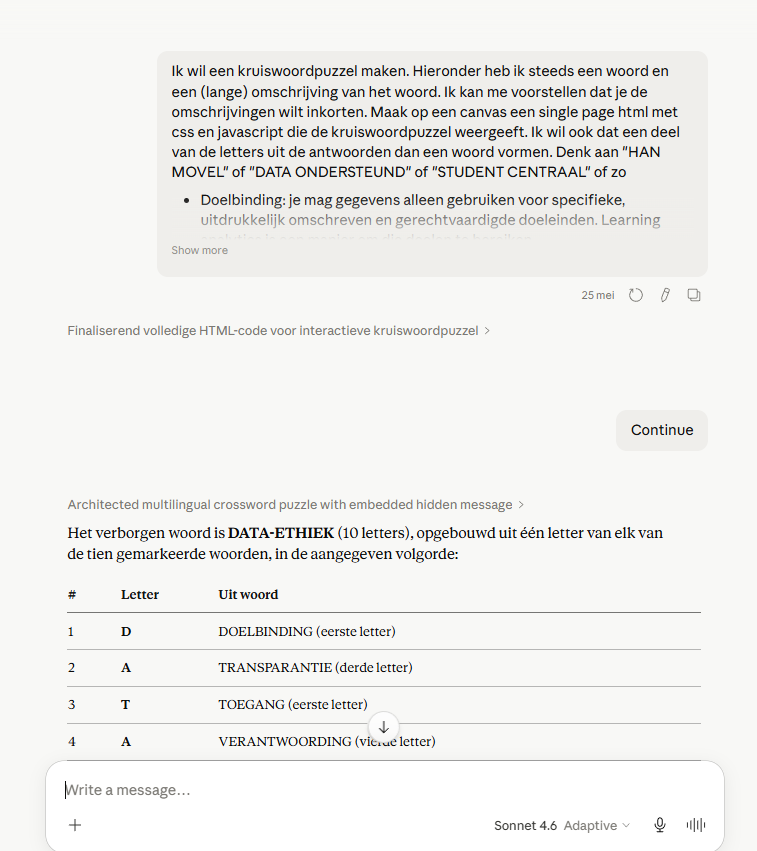
Daarop dacht ik “bekijk het maar, ik probeer het wel elders” en week uit naar AI-Studio van Google met Gemini 3.5 Flash. En daar kreeg ik in no time, meteen bij de eerste poging een correct werkende oplossing. Na nog twee tweaks (1 voor de interface en 1 voor het feit dat je ook “gefeliciteerd!” kreeg als je het systeem de juiste antwoorden liet invullen was hij klaar: Kruiswoordpuzzel 2026. Heel hoogstaand? Vast niet, maar ik ga er vanuit dat de studenten eruit gaan komen en dat het hoe dan ook leuker voor ze is dan wanneer ik al die beschrijvingen noem.
Zoals ik al zei: het is geen model-/leverancier-bashing. Het is het documenteren van een voorbeeld waarbij ik eigenlijk gedacht zou hebben dat beiden dit zouden moeten kunnen en de ene vreselijk nat ging. Met Qwen3.6:35b lokaal draaiend op mijn computer ging het in de agent ook niet overigens. Die raakte helemaal in de war tijdens het bedenken van een strategie. Kortom, 1 vraag/prompt, 3 modellen/harnassen, 3 verschillende uitkomsten. Goed om te onthouden.



