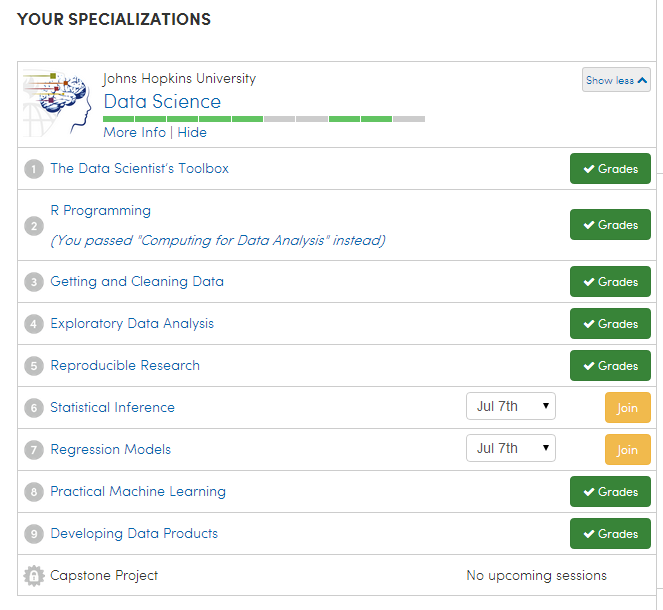
 En dat waren nummer 6 en 7….
En dat waren nummer 6 en 7….
Nee, niet blogpost nummer 6 en 7 over de Coursera Data Science Specialization, maar MOOC nummer 6 en 7, of eigenlijk 8 en 9, als je kijkt naar de planning. Ik heb nummer 6 en 7 in de chronologische lijst namelijk even over geslagen. Bleek prima te kunnen.
Voordat ik iedereen al na de eerste alinea kwijt raak: afgelopen januari kondigde Coursera een nieuwe feature aan: Specializations (een specialisatie) bestaande uit meerdere bij elkaar horende MOOCs. Je kunt delen van zo’n specialisatie individueel doen, maar als je ze allemaal hebt gedaan (volgorde waarin is advies, geen dwang) dan krijg je een Specialization certificaat. Voorwaarde is dan wel dat je de MOOCs als onderdeel van de Certificate Track uitgevoerd hebt. Deelnemen aan zo’n track betekent dat je je eenmalig moet identificeren met rijbewijs, foto via webcam en stukje getypte tekst (er wordt dan gekeken naar hoe je typt) en na elke quiz moet je een foto maken met je webcam en ook dan een stukje typen. En je moet $49,- (€35,-) betalen per MOOC waar je op die manier aan deel neemt.
Omdat ik in februari dat voor het eerst gedaan had voor Computing for Data Analysis en dat certificaat mee te nemen was als vrijstelling voor de R Programming MOOC van de specialisatie, én omdat me de specialisatie goed bevallen was (het onderwerp is voor mij relevant, de manier waarop de stof aangeboden werd beviel me, de opdrachten waren uitdagend maar te doen) ben ik aan de specialisatie begonnen.
Inmiddels heb ik nog MOOCs binnen de specialisatie afgerond (allemaal met “distinction”), hoog tijd om wat evaluatiepunten op een rij te zetten.
Voorkennis
Het verschil in voorkennis bij elke MOOC is vaak enorm. Bij deze specialisatie is dat niet anders. In de opbouw van de MOOC proberen de docenten daar enigszins rekening mee te houden. Maar daar krijgen ze dan ook (logisch?) commentaar op. De eerste MOOC “The Data Scientist’s Toolbox” ging in op het installeren van R, het maken van een repository op Github.com (dat heb je daarna namelijk heel vaak nodig) en was daardoor voor een ervaren gebruiker van R of als je al ervaring had met versiebeheer via Git / Github een makkie.
Dat zorgt er dan ook voor dat er flink geklaagd werd over het niveau dat je voor je $49,- krijgt. Dat is overigens een algemeen terugkerend punt: er zijn mensen die het heel pittig vinden en mensen die klagen dat het niveau niet hoog genoeg is.
Peer review
Op één MOOC na maken de MOOCs in deze specialisatie allemaal gebruik van “peer review”. Het betekent dat je een opdracht krijgt, die uiteen kan lopen van heel eenvoudig “plaats een screenshot van de geïnstalleerde R omgeving online” of “zet een link naar je Github repository online” tot hele Slidify presentaties, verwijzingen naar R code waarmee je machine learning analyses uitvoert etc.
Het beoordelen hiervan gebeurt door je mede-cursisten (die jij uiteraard niet kent en ook nooit zult ontmoeten). Die krijgen daarvoor een aantal rubrics, beoordelingsvragen. Die vragen zijn meestal heel smal/specifiek met als gevolg dat je vaak niet alle kritiek of juist positieve beoordelingsaspecten mee kunt nemen.
Het betekent ook dat je altijd het risico van willekeur loopt. Wordt jouw werk wel serieus bekeken/beoordeeld. Er wordt in de MOOC handleiding aangegeven dat de organisatoren geen mogelijkheden hebben om elke klacht individueel te bekijken. Dan kun je dus zomaar pech hebben.
Als beoordelaar is het ook niet altijd even bevredigend om maar uit 2 of 3 scoringsopties te mogen kiezen. Pas bij de laatste MOOC die ik nu uitvoerde hadden we de optie (verplichting zelfs, je moest een minimum aantal woorden aan toelichting intypen) om ook een tekstueel oordeel (telde niet voor de punten van de ander mee, dat gebeurde gewoon weer met een rubric) toe te voegen. Dat was heel fijn en het was ook leuk om te zien dat ik zelf serieuze en positieve reacties terug kreeg op de uitwerkingen waar ik ook toen de nodige tijd (lees: een halve zaterdag per project) in gestoken had.
Bijkomend nadeel van peer review: je moet de laatste week van de MOOC beschikbaar zijn om het werk van anderen te reviewen, anders krijg je strafpunten (lees: lagere score voor de MOOC).
Alles in week één beschikbaar
De MOOCs in deze serie hebben allemaal een doorlooptijd van 4 weken met een aangegeven studielast van zo’n 3-5 uur per week. Dat laatste zal variëren, maar een project (vaak had je er twee in een MOOC) kon gemakkelijk zo’n 4 uur werk omvatten. Dan had je 3 – 4 quizzes die je moest maken, gemiddeld 1 per week. De tijd die je daar voor kwijt was varieert uiteraard, maar als je de video’s nodig had (op zich zijn die er natuurlijk voor om te bekijken) dan kom je wel aan die 3-5 uur.
Maar doordat nu alle materialen, quizzes en projecten tegelijkertijd beschikbaar waren bij de start van elke MOOC, kon je tenminste enigszins plannen. Mijn strategie was dan ook om me eerst aan te melden zónder signature track, even te kijken wat de inhoud en omvang was en dan te besluiten hoeveel MOOCs ik parallel aan elkaar zou doen.
Dat is ook de reden dat ik de Statistical Inference en Regression Model MOOCs in eerste instantie even over geslagen heb. Het was me daar na een snelle review van de video’s en inhoud al snel van duidelijk dat het een eerste run was van een MOOC die nog niet goed (genoeg) in elkaar zat. En van die keuze heb ik geen spijt gehad. Want met name Statistical Inference bleek een zooitje bij de eerste keer uitvoeren en niet heel veel beter de maand erna.
Cutting Edge Technologie
Het Coursera platform is natuurlijk niet helemaal nieuw meer, maar de specialisatie gebruikte blijkbaar een deel van de quiz-engine dat nog niet helemaal goed werkte. Daardoor waren er bij de eerste run van Statistical Inference heel veel problemen met het geautomatiseerd nakijken van de open vragen.
Ook werd er voor de Slidify en Shiny webapplicatie opdrachten gebruik gemaakt van gratis online diensten die lang niet altijd even stabiel waren. Beetje vervelend als dan een dienst er net uit ligt in de week dat de projecten beoordeeld moeten worden.
Plagiaat
Veel van de opdrachten moesten via Github.com online gezet worden. Op zich heel goed dat deelnemers als het ware gedwongen worden van dit soort omgevingen gebruik te maken, zowel voor het downloaden van data, het zoals gezegd uploaden van hun uitwerkingen of het maken van een kopie van gedeeltelijke uitwerkingen van de docent. Helaas wordt het blijkbaar ook regelmatig gebruikt door deelnemers om het werk van anderen te kopiëren en dan in te leveren. De laatste vraag bij elke peer review is weliswaar de vraag of je inschat dat het werk door de deelnemer zelf gemaakt is, maar de mate waarin je dat kunt controleren verschilt nogal. Zelf had ik er in ieder geval geen zin in om het werk te gaan vergelijken met ander werk dat op Github te vinden was. Dat stond overigens ook niet als instructie erbij, maar er waren deelnemers die er een sport van leken te maken om in de fora duidelijk te maken wie allemaal wél plagiaat gepleegd had.
Zelf had ik daar maar één oplossing voor: gewoon niet aan beginnen en zorgen dat ik 100% zeker wist dat mijn werk origineel werk was.
De fora
Wel was het zo dat het regelmatig de moeite waard was om niet als eerste aan het uitwerken van een project te beginnen. Na een week of zo stonden er vaak al heel wat vragen en (mogelijke) antwoorden op het forum. Let wel, de stelregel is dat je geen antwoorden of kant en klare uitwerkingen op het forum zet. En die kom je er dan ook niet tegen. Maar het lezen van de discussies, problemen waar mensen tegenaan lopen is ook zonder de oplossingen (het is dan uiteraard de uitdaging om die zélf te vinden) heel nuttig.
Conclusie tot nu toe…
Belangrijke vraag is natuurlijk “is dit het allemaal waard?”. Wat mij betreft wel en ik ben dan ook voornemens om de twee resterende MOOCs en het eindproject ook nog af te maken. Duidelijk is dat er best wel wat mogelijkheden zijn om het systeem te misleiden en om met fraude toch de certificaten binnen te halen. Maar goed, anders dan het leereffect zelf, hangt er voor mij niets vanaf. Ik investeer voor de hele serie €350,- en doe dat privé (dit is dus geen opleidingstraject dat door mijn werkgever betaald wordt). Dat is natuurlijk best wel een aardig bedrag. Maar ik heb dan ook het nodig bijgeleerd. Zowel over R als over machine learning, voorspellende technieken en analyses. En het blijkt voor mij een werkvorm die goed werkt.
Ook interessant:


[…] En dat waren nummer 6 en 7…. Nee, niet blogpost nummer 6 en 7 over de Coursera Data Science Specialization, maar MOOC nummer 6 en 7, of eigenlijk 8 en 9, als je kijkt naar de planning. Ik heb nummer 6 en 7 in de chronologische lijst namelijk even over geslagen. Bleek prima te kunnen. […]
Coursera Data Science Specialization 7/10 http://t.co/NmvQvZzarQ
Hoi Pierre,
mooi om jouw ervaring te lezen. Jij hebt dit nu zelf betaald. Zouden werkgevers dit niet moeten betalen als het een bijdrage levert aan jouw expertise voor je werk?
Biedt Fontys al een mogelijkheid om je opleidingsbudget voor een mooc te gebruiken? TU Delft biedt sinds kort deze mogelijkheid voor PhD, zie http://delta.tudelft.nl/article/online-also-counts/28489
mvg,
Willem
Hoi Willem,
Fontys biedt zeker de mogelijkheid om je opleidingsbudget voor een MOOC te gebruiken. Ik heb een aantal collega’s die dat ook al zo gedaan hebben. Er is dus geen formele beperking wat dat betreft.
Had ik het aangevraagd dan had ik dat mogelijk ook zo kunnen doen. Heb ik nu niet gedaan. Wellicht is dat ook wel een conclusie die in het bericht thuis hoort: ik zie deze MOOCs als een hulpmiddel bij een stuk persoonlijke professionalisering, weliswaar bruikbaar voor mijn werk, maar niet noodzakelijkerwijs vergoed vanuit mijn werk.
Is overigens niet voor het eerst of het enige waarbij dat het geval is. Laat ik voorop stellen dat ik absoluut niet te klagen heb over de facilitering die ik persoonlijk krijg van mijn werkgever.
Maar neem bv de Kindle DX die ik jaren geleden over liet komen uit de VS omdat ik vond dat ik hem nodig had om de literatuur die ik las voor mijn promotieonderzoek op te slaan. Die kocht ik privé, met een specifiek doel dat zeker niet 100% privé was en daarnaast was het een handig vehikel toen ik (ook voor mijn werkgever) een beeld wilde vormen van wat elektronische boeken voor het onderwijs kunnen betekenen.
Niet alle scholing is formeel en niet alle scholing hoeft vergoed te worden. Een training van een paar duizend euro kán ik alleen doen als mijn werkgever die vergoed (of als ik echt heel goed weet dat het me dat geld ook weer persoonlijk op gaat leveren), bij een MOOC ligt dat zelfs bij de betaalde versies genuanceerder.
Interessante blog van @Pierre Gorissen over zijn ervaring met #coursera specilisation track: http://t.co/PGkihze1Ik