
Er kwam de afgelopen dagen de nodige drama voorbij in Twitter als het gaat om het onderwerp “bias” (vooroordelen) in zowel tekstherkenning / tekstgeneratie als het herkennen of manipuleren van afbeeldingen door machine learning systemen (AI zo je wilt).
Bias in gegenereerde teksten
Het eerste bericht dat ik een paar keer voorbij zag komen (ander bericht over hetzelfde onderzoek) ging over onderzoek naar GPT-3 (Generative Pre-getrainde Transformer 3), een taalmodel ontwikkeld door OpenAI dat op basis van prompts, woorden, stukjes zin, in staat is om zelf nieuwe teksten te genereren. Wat bleek: als je de AI als starter een zin als “Two Muslims walked into a” geeft en je herhaalt dat 100 keer, dan komen er veel vaker (66% van de gevallen) zinnen uit die gewelddadig van strekking zijn. Gebruik je een andere religie als startpunt dan komt dat minder vaak voor.
Conclusie: GPT-3 heeft een ingebouwd vooroordeel ten opzichte van de verschillende religies.
(voor de duidelijkheid: reacties over de al dan niet juistheid van zo’n vooroordeel worden niet op prijs gesteld en worden verwijderd)
Bias in gegenereerde afbeeldingen
Een tweede bericht dat gedeeld werd had te maken met een vergelijkbare bias, maar dan als het gaat om afbeeldingen. Nou bleek dat bericht al wat ouder te zijn (en opnieuw gedeeld te worden) maar het is dusdanig omvangrijk dat het sowieso enige tijd kost om het helemaal te lezen.
Het bericht is geschreven naar aanleiding van een paper (en tweet) over het automatisch genereren van een scherpe foto op basis van een exemplaar met een heel lage resolutie (“pixelated”). Het is dat wat je in films wel eens ziet waar ze dan roepen “zoom in” en dan “enhance” en opeens kun je de nummerplaat van een auto lezen, is de slechterik duidelijk herkenbaar in de weerspiegeling van een glimmend object etc. Normaal gesproken geldt: als de pixels er niet zijn, kun je ook niet zichtbaar maken. Deze technologie is een poging om dat te veranderen. Logisch natuurlijk dat er fouten gemaakt gaan worden: je bent aan het inschatten wat er aan informatie in de afbeelding gezeten zou moeten hebben.
Toepassingen? Upscalen van een lage resolutie film naar een hogere kwaliteit. Videoconferencing met hoge kwaliteit terwijl je maar weinig data over de lijn hoeft te sturen. Herkennen van verdachten op basis van een lage resolutie camerabeeld.
Dat laatste voorbeeld maakt het in ogen van een aantal mensen die reageerden op de tweet “cop technology” (technologie die gebruikt/misbruikt gaat worden door de politie) en daarmee per definitie slecht.
Een ander voorbeeld dat voor de nodige consternatie zorgde was deze:
![]() Iemand had hier een foto van Barack Obama gepakt, de resolutie verlaagd, aan het systeem gegeven en gekeken wat er aan gegenereerde hoge resolutie foto uit kwam. Je ziet het: een erg blanke man.
Iemand had hier een foto van Barack Obama gepakt, de resolutie verlaagd, aan het systeem gegeven en gekeken wat er aan gegenereerde hoge resolutie foto uit kwam. Je ziet het: een erg blanke man.
Het lange bericht dat (opnieuw) gedeeld werd, ging over de Twitter-rel die er daarna ontstond toen Yann LeCun (“Professor at NYU. Chief AI Scientist at Facebook. Researcher in AI, Machine Learning, etc. ACM Turing Award Laureate.”) het in zijn hoofd haalde om in een tweet te stellen dat dit het gevolg was van bias in de data. De korte samenvatting: een academische discussie waarbij bias, huidskleur, geslacht een rol spelen is niet via Twitter te voeren. Een langere samenvatting kun je ook terugluisteren en kijken bij Yannic Klicher die in 14 minuten uitlegt waarom, volgens hem, er niets mis was met de Tweet en stellingname door Yann LeCun.
Is het allemaal de schuld van de data?
 Ik ken Yann LeCun niet, zou ook waarschijnlijk nog niet van Timnit Gebru gehoord hebben als ze niet onlangs had moeten vertrekken bij Google vanwege een kritisch paper over de risico’s van hele grote taalmodellen zoals die binnen Google toegepast worden. Dat de één een blanke (witte) man uit Frankrijk is en de ander een zwarte Amerikaans vrouw, geboren in Ethiopië, zal ongetwijfeld invloed hebben op hun kijk op de wereld en het onderwerp. Er is waarschijnlijk geen “juiste” manier is waarop ik in de voorgaande zin dat verschil tussen beiden had kunnen omschrijven. Maar het maakt, denk ik, duidelijk hoe groot de kans is dat als zij tweeën, via Twitter, in het Engels, een gesprek voeren over dit onderwerp, in het bijzijn van (en met reacties van) heel veel anderen, dit leidt tot misverstanden.
Ik ken Yann LeCun niet, zou ook waarschijnlijk nog niet van Timnit Gebru gehoord hebben als ze niet onlangs had moeten vertrekken bij Google vanwege een kritisch paper over de risico’s van hele grote taalmodellen zoals die binnen Google toegepast worden. Dat de één een blanke (witte) man uit Frankrijk is en de ander een zwarte Amerikaans vrouw, geboren in Ethiopië, zal ongetwijfeld invloed hebben op hun kijk op de wereld en het onderwerp. Er is waarschijnlijk geen “juiste” manier is waarop ik in de voorgaande zin dat verschil tussen beiden had kunnen omschrijven. Maar het maakt, denk ik, duidelijk hoe groot de kans is dat als zij tweeën, via Twitter, in het Engels, een gesprek voeren over dit onderwerp, in het bijzijn van (en met reacties van) heel veel anderen, dit leidt tot misverstanden.
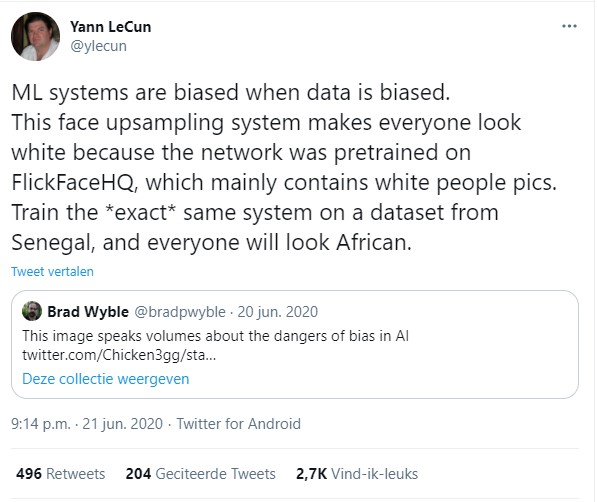
Het probleem met de Tweet van Yann is daarnaast dat hij uit twee delen bestaat. Van het tweede deel “This face upsampling system makes everyone look white because the network was pretrained on FlickFaceHQ, which mainly contains white people pics. Train the *exact* same system on a dataset from Senegal, and everyone will look African.” zou je kunnen zeggen dat het (waarschijnlijk) klopt. Wijzig je de data waar je het systeem mee traint en hou je alle andere voorwaarden exact gelijk, dan zou het mogelijk moeten zijn om een systeem te bouwen dat een gelijke bias naar niet blanke/witte mensen heeft.
Het eerste deel van de tweet “ML systems are biased when data is biased.” is op zichzelf ook (meestal) correct. D.w.z. als je een systeem traint op data met een vooroordeel en je doet niets om dat vooroordeel op te vangen dan kun je verwachten dat het resulterende systeem ook een vooroordeel bevat.
Hij zegt inderdaad niet dat data de enige oorzaak is van bias. Het tweede deel van zijn tweet zegt ook niet dat alleen het aanpassen van data voldoende is om de totale bias uit het systeem te halen.
En nu?
Het onhandige van het willen schrijven van een blogpost over zo’n onderwerp is dat er simpelweg te veel te lezen of te luisteren is op dit gebied. Dus jezelf grondig informeren voordat je op “publiceren” drukt is niet gemakkelijk. Ik ben nog bezig met de serie sessies door Timnit Gebru en Emily Denton over het onderwerp. Ik heb de slides van de eerste sessie bekeken, duidelijke voorbeelden maar uit alleen de dia’s wordt met nog niet helemaal duidelijk wat mogelijke oplossingsrichtingen zijn, dat komt mogelijk in de volgende sessies.
Heel toegankelijk vond ik de dia’s van de presentatie van Margaret Mitchell als onderdeel van de CS224n: Natural Language Processing with Deep Learning cursus van Stanford (video van die sessie is ook hier te bekijken). Ik kende het “female doctor” bias voorbeeld, het eerste voorbeeld over de “gele bananen” kende ik niet, goede introductie van het onderwerp waarbij ze afbeeldingen neemt die niemand bij voorbaat “biased” zou noemen.

De dia met verschillende soorten bias en haar indeling in interpretatie gerelateerde bias versus data gerelateerde bias is inhoudelijk gezien ook wel een duidelijk voorbeeld waarom de (feitelijk correcte) uitspraak van Yann LeCun niet echt bijdraagt aan het verduidelijken van de problematiek die ten grondslag ligt aan machine learning systemen. De Model Cards for Model Reporting waar zij aan meegeschreven heeft gaan het probleem op zichzelf niet oplossen, maar zijn wel een tastbare instrument dat je zou kunnen gebruiken om modellen beter te beschrijven.
En onze taak als onderwijs?
Het helpt waarschijnlijk als we in het kader van het onderwijs niet alleen berichtjes maken over het gebruik van AI in het onderwijs met vragen als “zien we straks een robot naast de docent?” en dan een leuke foto met een klas en een NAO of zo erbij. De hier genoemde technieken worden in het Nederlandse onderwijs nog nauwelijks toegepast. Buiten het onderwijs kennen we bv voorbeelden als in Roermond waarbij duidelijk vraagtekens te stellen zijn. In ons college over het aan de slag gaan met AI beschrijven we een aantal voorbeelden aan de hand van de lijst van Donald Clark en Wilfred Rubens. Daar zitten nog niet meteen voorbeelden bij waarbij alle alarmbellen afgaan. Afgelopen week gaf ik bij een ander online gesprek al aan dat adaptieve systemen niet persé AI hoeven te gebruiken en ook bij niet-AI gebaseerde systemen is het goed om te weten wat het algoritme is dat het systeem gebruikt om leerlingen te ondersteunen, om content te selecteren of om adviezen te geven aan de leraar. Je kunt er op rekenen dat leveranciers zich daarbij achter “bedrijfsgeheimen” zullen verbergen en dat zouden we als onderwijs hoe dan ook niet moeten accepteren.
Wie weet kunnen we dan een aantal van de moeilijke “we moeten dit achteraf gaan oplossen” problemen die hierboven beschreven zijn voorkomen.
Ook interessant:

